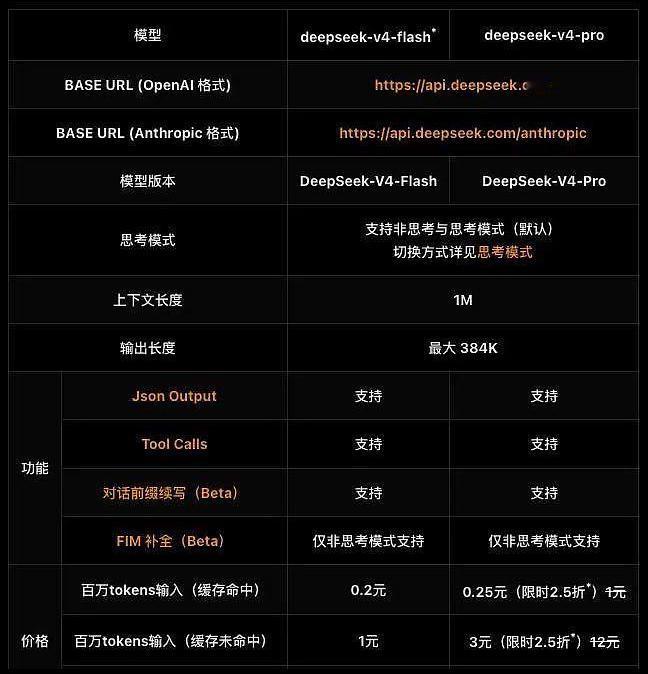
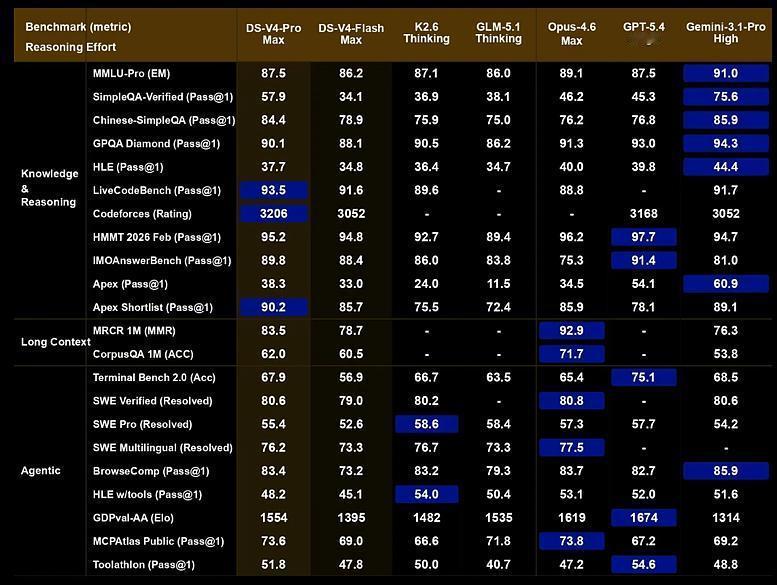
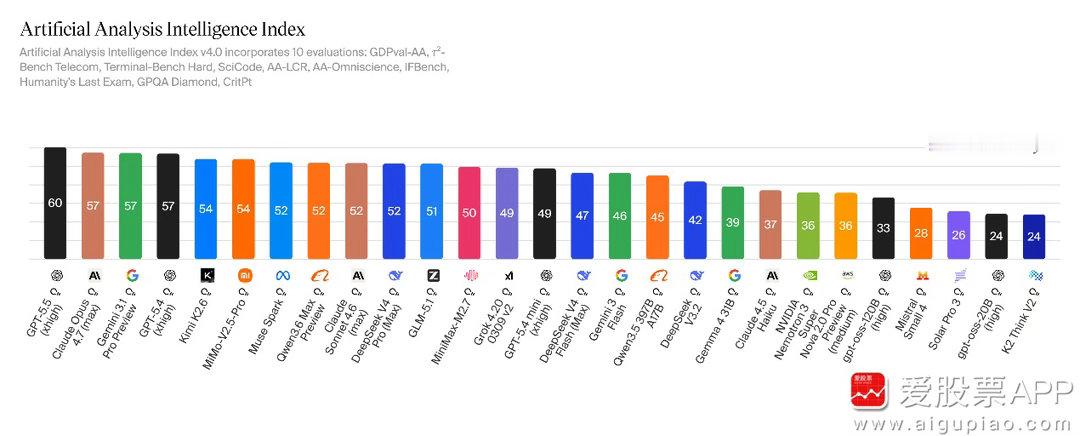
这个周末大家关注度高的还是DeepSeek-V4的发布会,其路线是主打极致降本(如何用最少的钱达到海外TOP级水准)。DeepSeek后续仍有系列降本措施,一方面将推进算力层面优化与超级电力配套的结合,另一方面后续模型小版本将剔除当前版本中不必要的过度优化措施,进一步降低Pro和Flash版本的token消耗。价格方面,2026年内Flash版本价格可降至1元/百万token以下,Pro版本价格可降至10元/百万token以下,仅为当前GPT 5.5(200余元/百万token)价格的几十分之一,将带动全球范围内对DeepSeek类高性价比大模型的调用量大幅增长。
如今核心驱动逻辑在于用户已形成“更多token调用可获得更高智能输出”的共识,随着大模型价格下探到可接受区间,调用需求将快速释放。核心消耗场景为Agent类应用,包括电脑端、端侧、手机端的各类Agent应用,这类应用可通过持续调用token提供自动化服务,对token需求量极大。
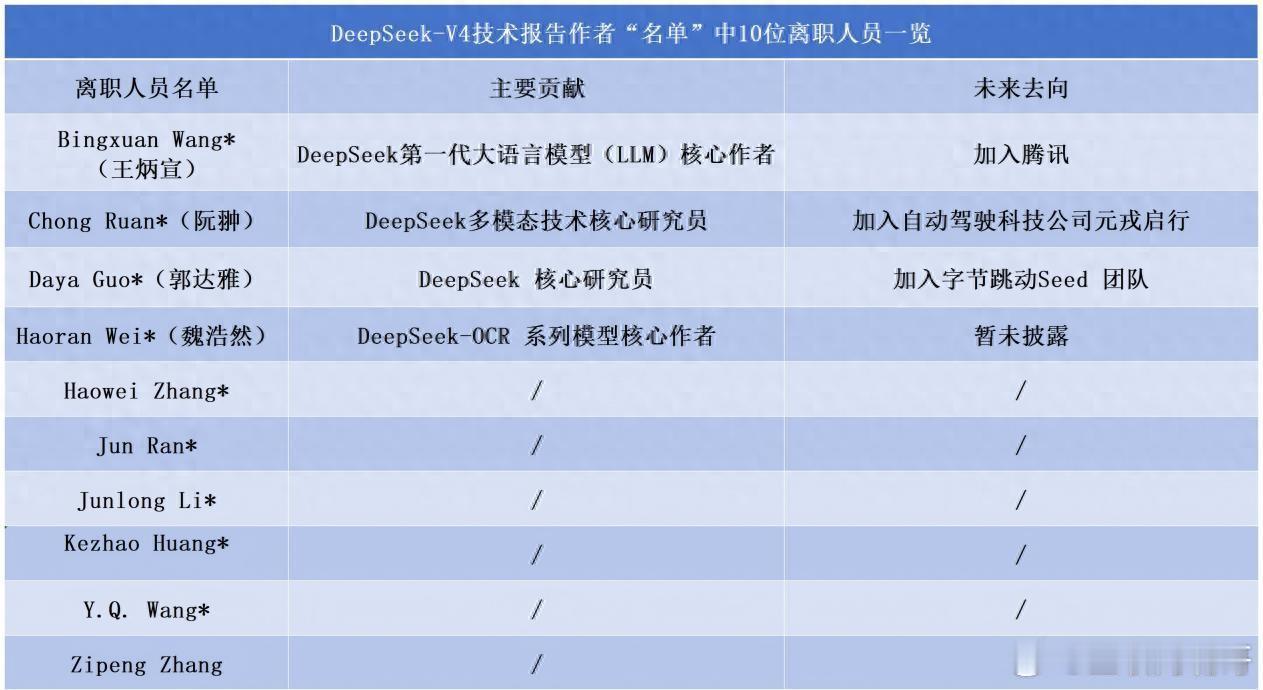
不过,DeepSeek并非不具备多模态研发能力,多模态团队在R1时代就已成立,此前团队独立开展多模态研发,未将相关能力与主版本模型融合。关于多模态能力的推出时点与路径:较强的多模态能力预计在下次旗舰大版本推出,小版本阶段有两种实现多模态功能的路径,一是小版本单独更新多模态能力供大模型调用,二是后续小版本迭代中通过Agent外挂多模态能力,但两种路径的实现效果均不及大版本原生融合,本次布局节奏并非技术能力不足导致,而是为控制版本发布周期做出的选择。