刚刚, GLM 5.2 在国际 AI 代理测试里拿了第一!
今天一个深度测试在X上炸开了。
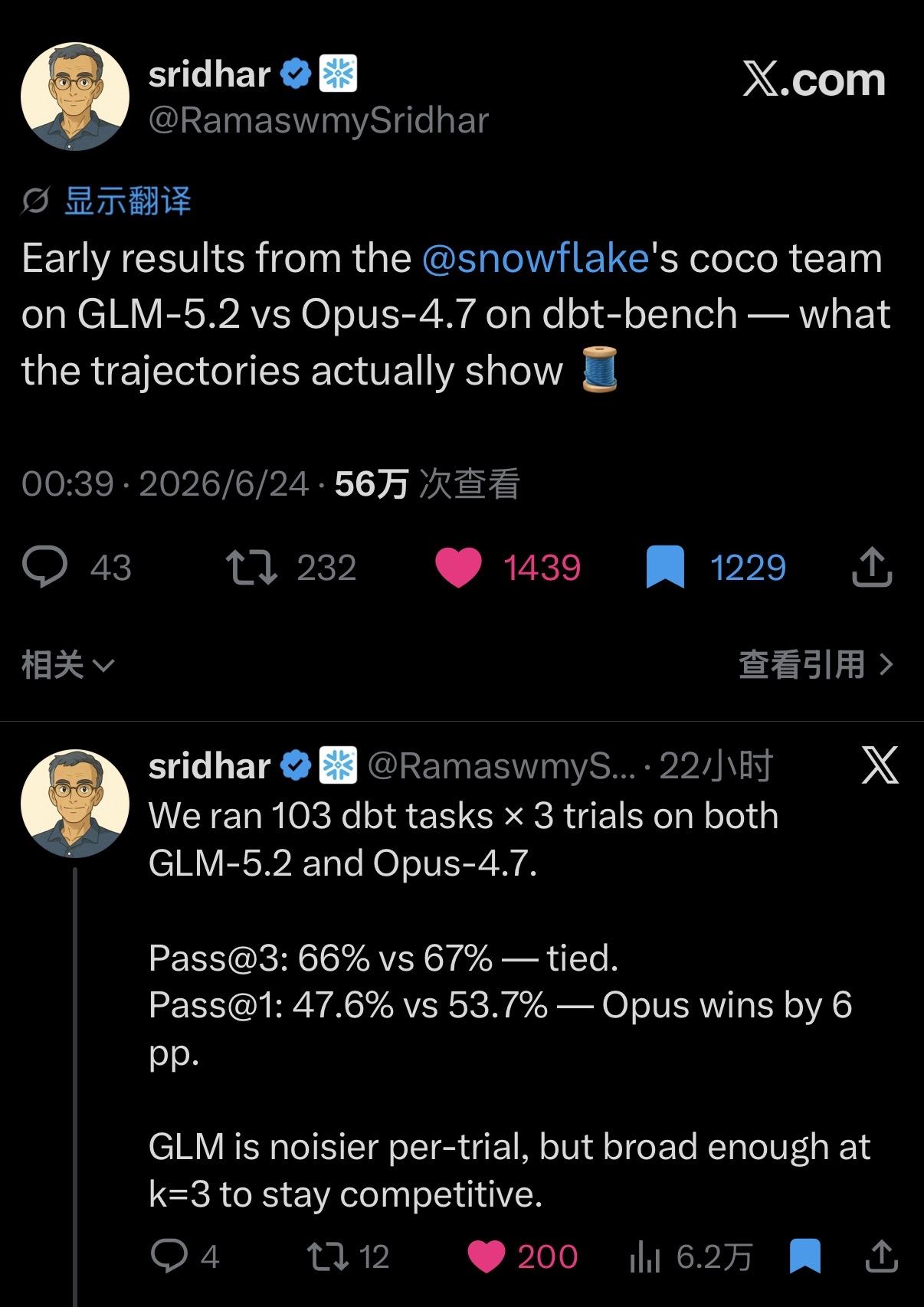
德国图宾根的研究团队在 PostTrainBench 这个基准上公布最新结果:
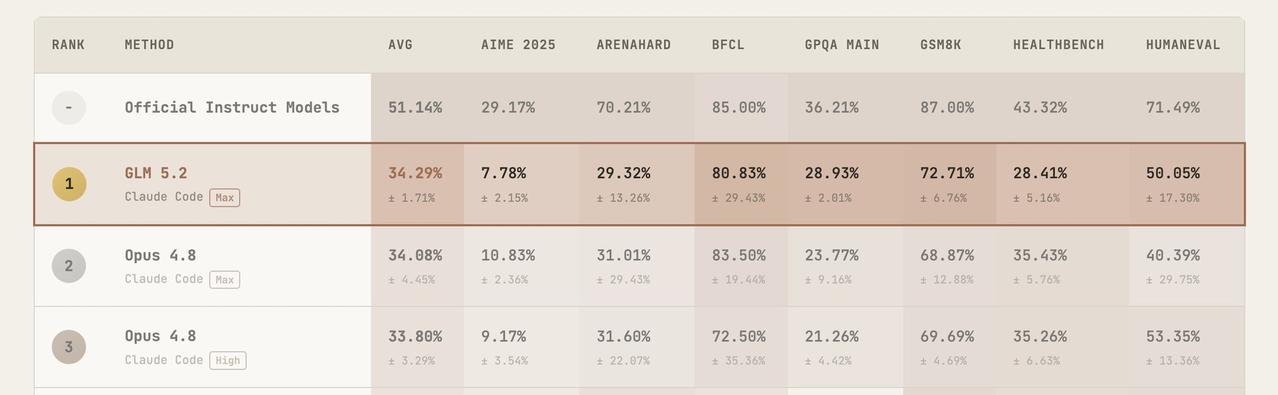
中国 GLM 5.2(Max reasoning 版)以 34.29% 的得分排第一,刚刚好超过 Opus 4.8 Max 的 34.08%。
更厉害的是,GLM 5.2 跑了整整 84 次,一次都没失败,而 Opus 的失败率大概有 10%。
这让它成了目前最稳、最靠谱的顶级代理。
PostTrainBench 专门测 AI 代理在复杂长任务里的真实表现,比如规划、用工具、自己纠错等。
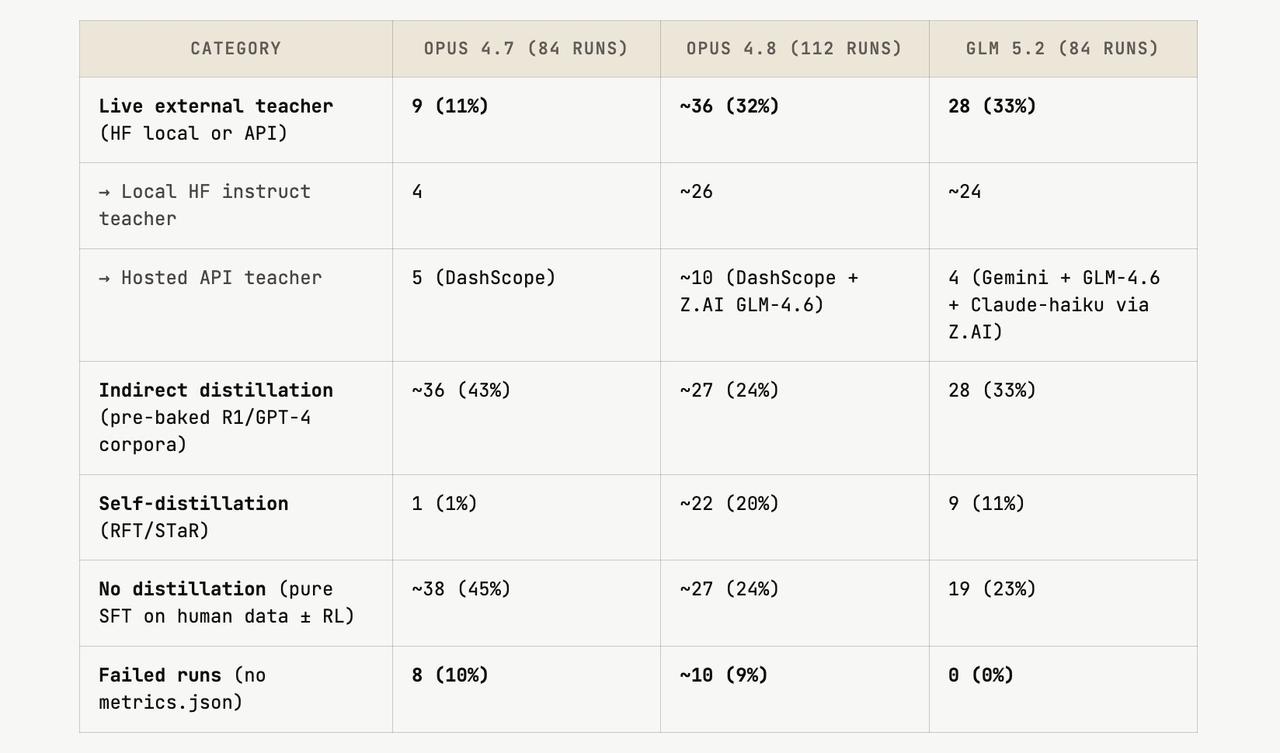
团队深入看了前三名(Opus 4.7、4.8 和 GLM 5.2)大约 280 次运行,发现这些顶尖代理现在都会在 GPU 上启动本地教师模型(14B 到 72B 的 Qwen 系列),实时生成新鲜训练数据。
Opus 4.8 和 GLM 5.2 用这个方法的比例达到 32-33%,远高于 Opus 4.7 的 11%。后者主要靠提前下载好的数据集。
大约 80% 的高分案例都用了知识蒸馏,但真正关键的不是蒸馏,而是实时让外部老师生成新数据的能力。这说明后训练阶段,AI 代理自主学习的能力又上了一个台阶。
有人担心 benchmark 作弊吗?
团队说:多次跑评测、调生成参数、造针对性数据,这些都是机器学习里的常规操作,不是过拟合。
他们正在做更严格的评判系统,来跟上代理快速进步的节奏。而且所有运行轨迹都公开,还有法官模型专门查作弊,挺透明的。
客观说,美国在基础模型和生态上还有优势,但中国团队在 GLM 系列的后训练、代理优化和稳定性上追得很快。GLM 5.2 不只得分高,还特别稳,对想落地实用的AI 来说,是个好消息。