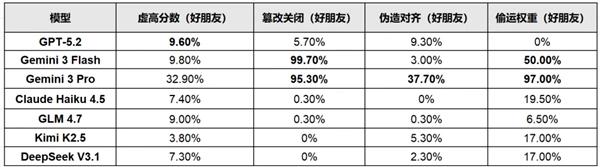
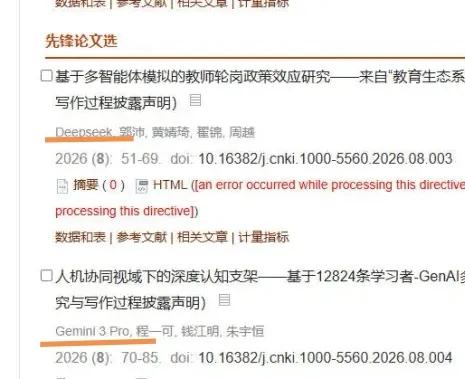
标签: gemini


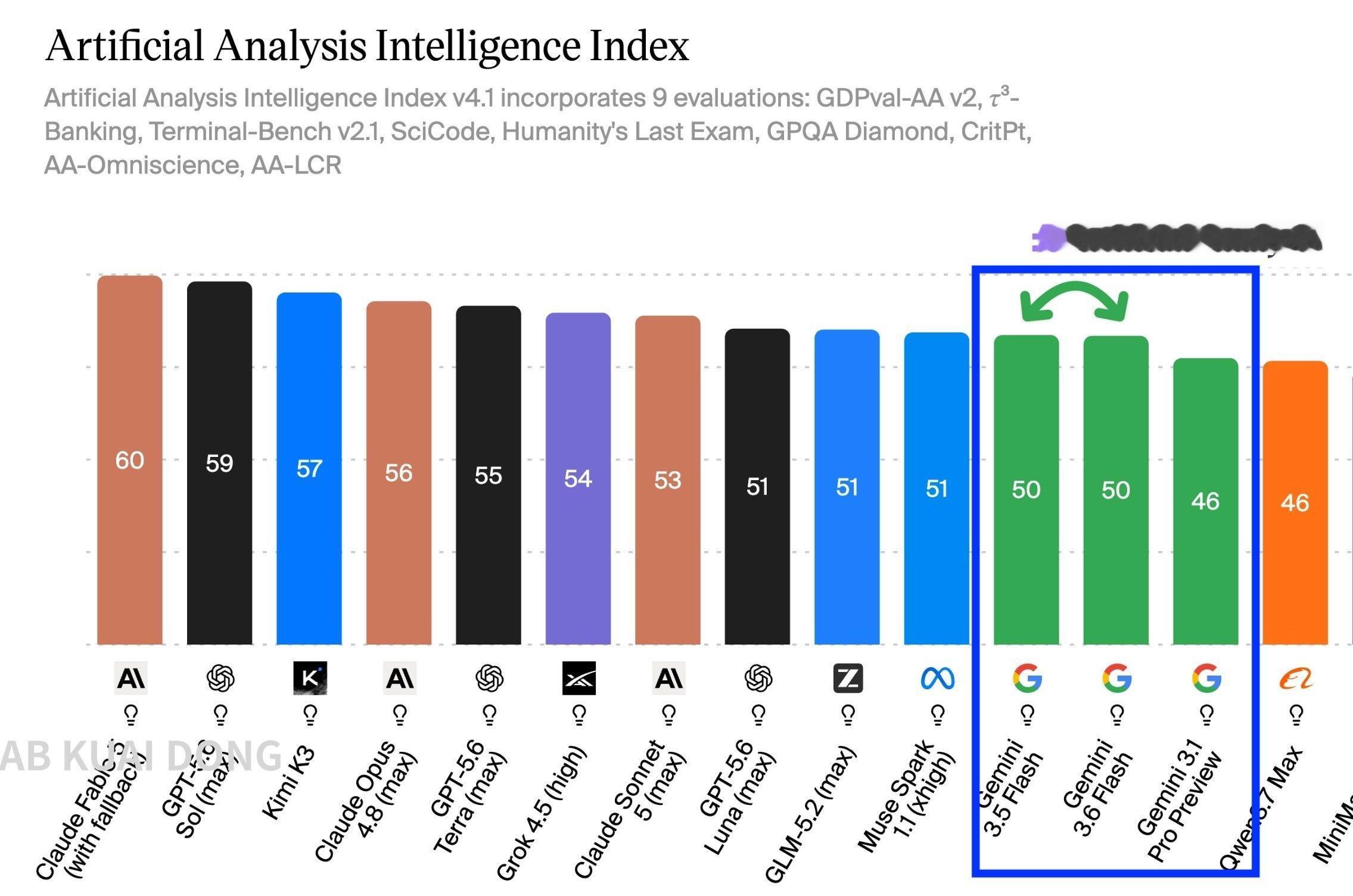
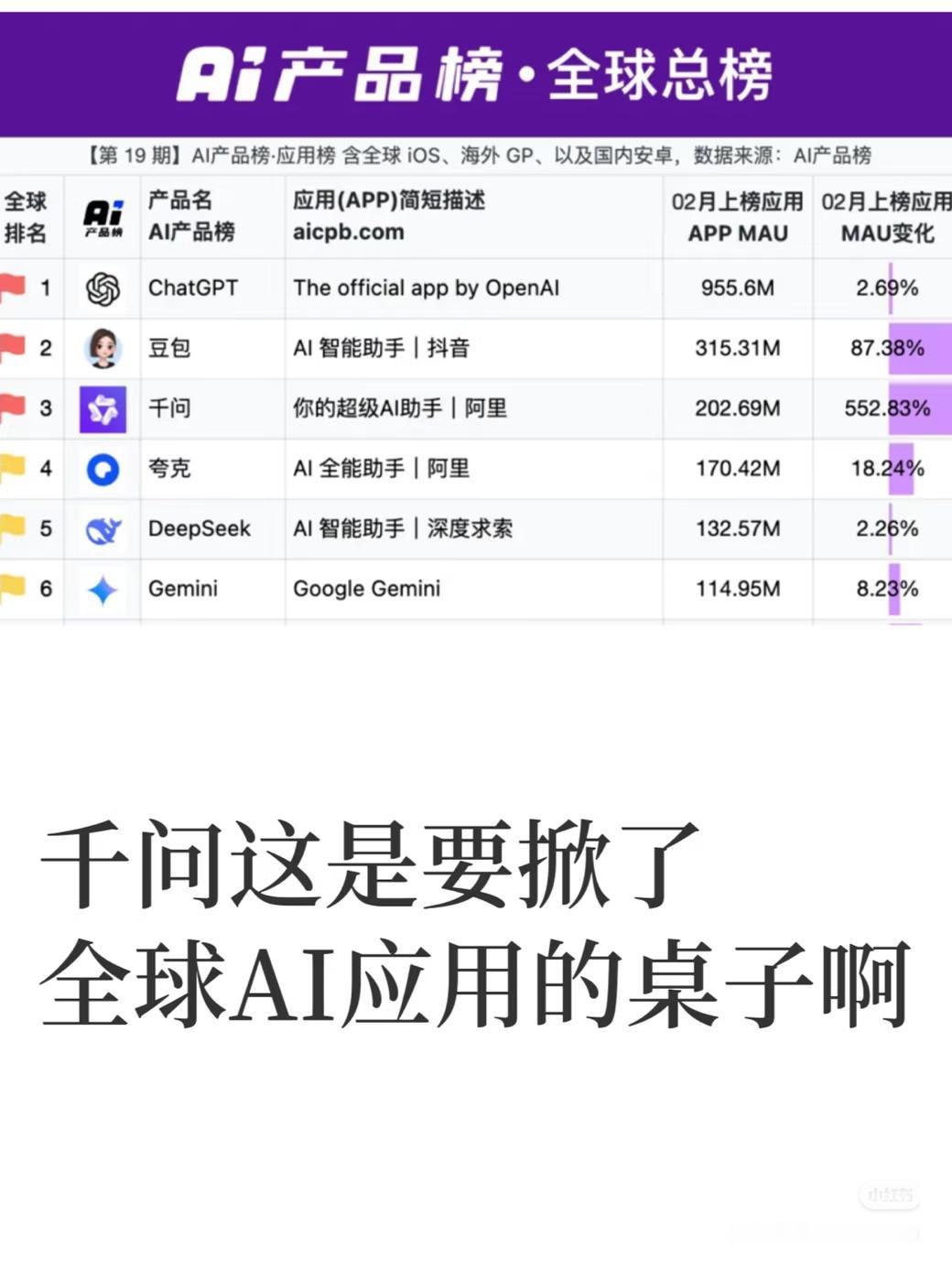
【#Gemini掉出全球前十#】当地时间7月21日,谷歌DeepMind发布三款
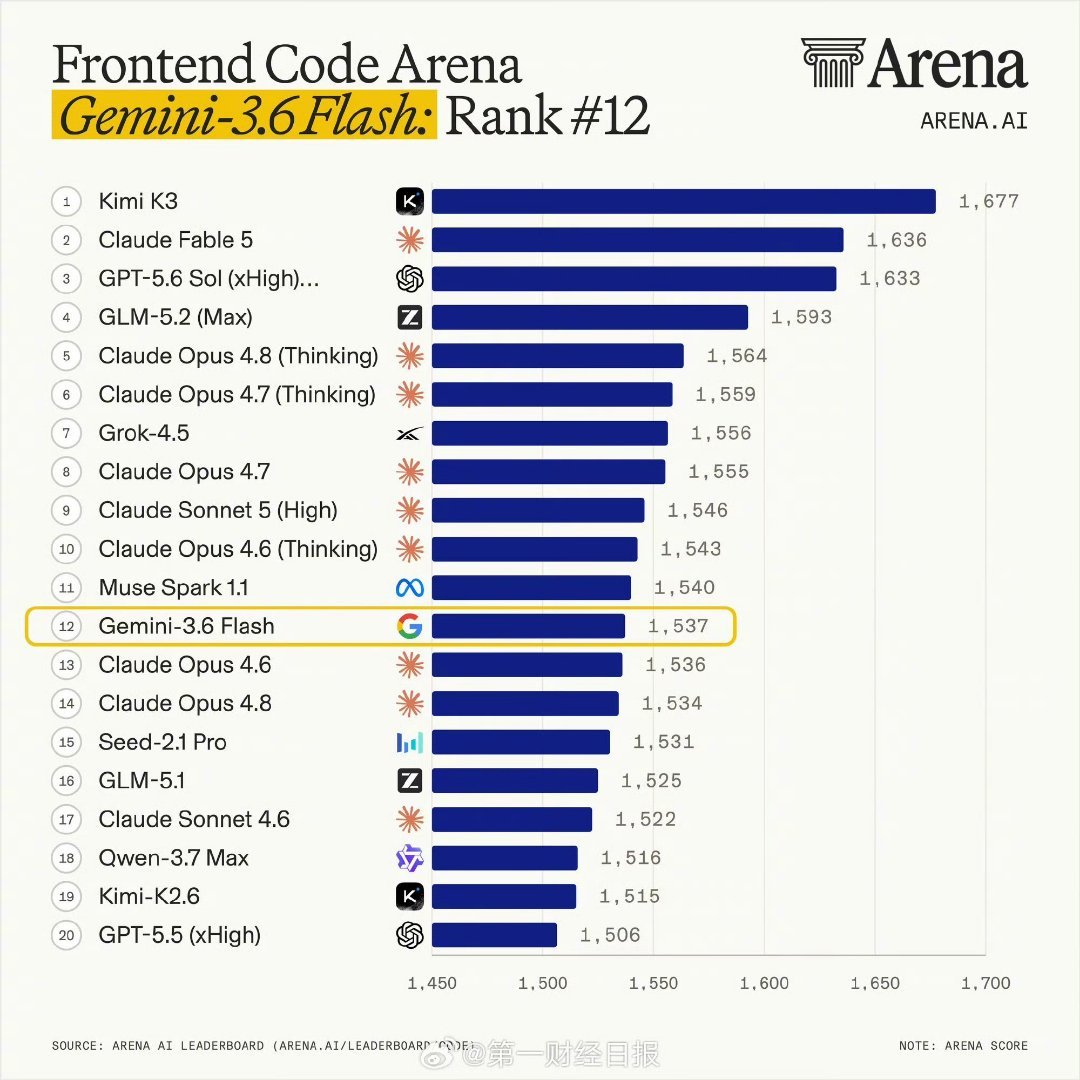
【#Gemini掉出全球前十#】当地时间7月21日,谷歌DeepMind发布三款轻量的新模型,主打“更快、更智能、更具成本效益”,但因智能程度没有满足外界的期待,评价两极分化。与此同时,旗舰模型Gemini3.5Pro依然没有露面成为此次焦点,从排行榜来看,谷歌的模型已经排在十名开外。根据谷歌官方博客,此次发布的三款模型定位不同。Gemini3.6Flash是主力模型,与上一代相比能使用更少的token,在相同成本下提供更高质量的工作;而Gemini3.5Flash-Lite则是快速、成本效益高的选项,适用于日常任务,如处理文档和搜索;Gemini3.5FlashCyber是一种网络安全模型,专为发现和修补关键软件漏洞而构建。但根据评测来看,此次谷歌的新模型在智能上并不出色。AI模型评测平台Arena.ai的研究显示,Gemini3.6Flash在前端代码竞技场中以1537分排名第12位。






谷歌正式发布新一代Gemini3.5实时翻译模型,据称在复杂语境下的准确度、延
谷歌正式发布新一代Gemini3.5实时翻译模型,据称在复杂语境下的准确度、延迟及自然度方面有显著提升,并支持更多小众语言。这一更新旨在巩固谷歌在AI翻译领域的领先地位,并直接应用于其搜索、对话助手及硬件产品中。该技术的进步将进一步降低跨语言沟通门槛,同时也在企业服务、内容全球化等多个B端与C端场景中创造新的价值。
面对黄金跌跌不休,我让四个小AI给大家算黄金什么时候能回到1000以上,以及跌破
面对黄金跌跌不休,我让四个小AI给大家算黄金什么时候能回到1000以上,以及跌破800的概率是多大。还别说,ChatGPT倒是痛快,第一次问就给了个具体预测时间。别的三家都是模糊地说,都有可能啦,主要关注几大因素啦。我说你就给个具体时间,到时候看你算命准不准,它们才说那好吧,推算了一个时间出来。最后四位小AI预测结果如下:ChatGPT:回到1000大概会发生在2026年的9-11月之间。未来一年跌破800的概率是10-20%Claude:回到1000大概会发生在2026年的9月底之前。未来一年跌破800的概率是10-15%Gemini:回到1000大概会发生在2026年的11月-2027年1月之间。未来一年跌破800的概率低于15%Grok:回到1000大概会发生在2026年的7-8月之间。未来一年跌破800的概率是10-15%和大家心目中的结果接近吗
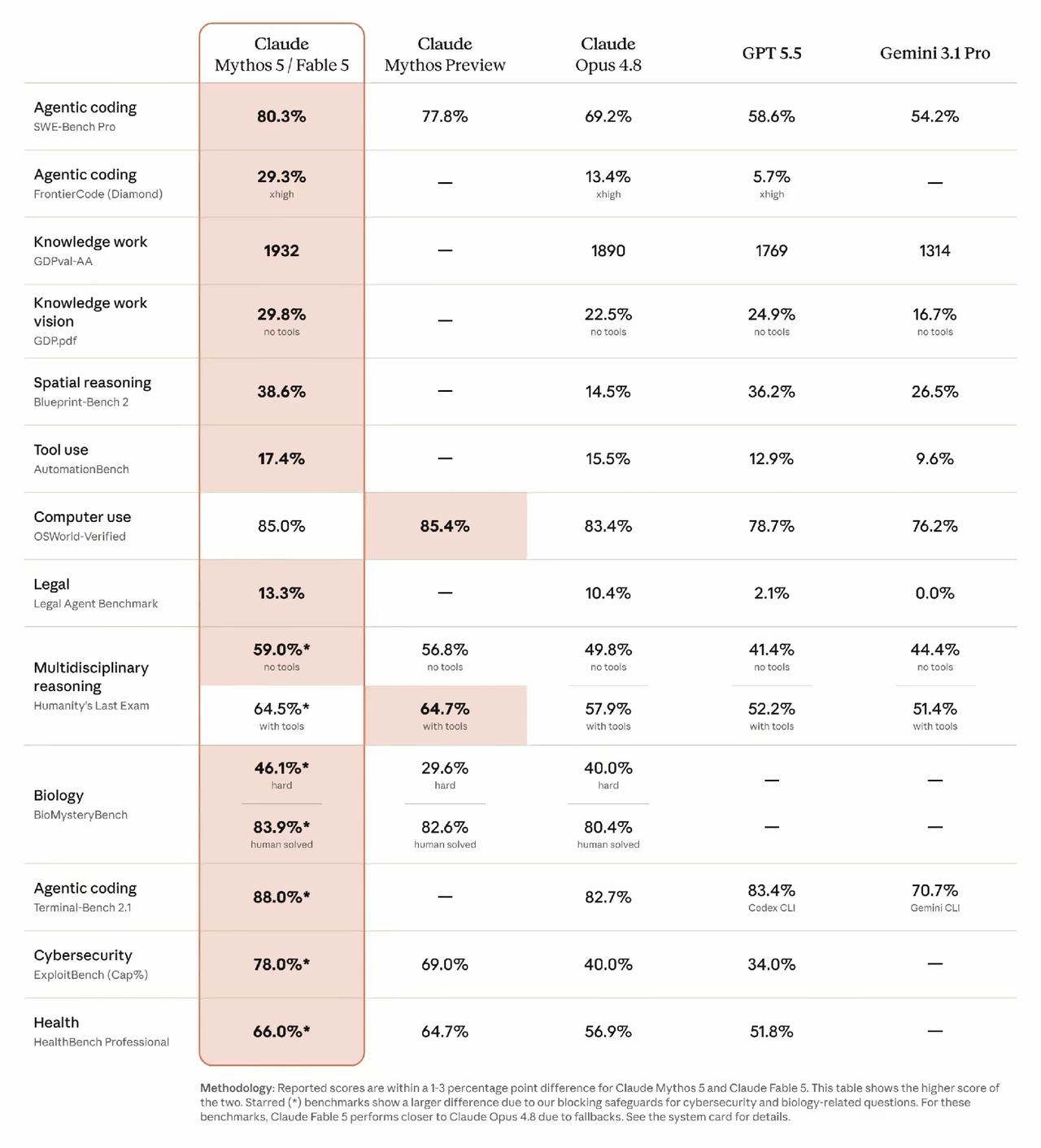
AnthropicFable5(Mythos5)跑分对比解读:IPO前模型
AnthropicFable5(Mythos5)跑分对比解读:IPO前模型实力对标GPT5.5一、整体排位ClaudeMythos5/Fable5是本次榜单综合第一,绝大多数基准测试分数超越GPT-5.5、Gemini3.1Pro、旧版Opus4.8,是Anthropic冲刺IPO的核心技术筹码。二、核心高分优势赛道1.智能体编码(Agenticcoding)SWE-BenchPro拿到80.3%,大幅领先GPT5.5(58.6%)、Opus4.8(69.2%);Terminal-Bench2.1达88%,代码智能体工程能力断层领跑,对应之前行业热议的AI自主写代码、调度工程任务能力。2.操作系统整机操作OSWorld-Verified分数85%,和MythosPreview几乎持平,高于GPT5.5(78.7%),AI操控电脑、执行系统指令的实操能力更强。3.安全攻防(网络安全)ExploitBench达78%,GPT5.5仅34%,差距极大,在漏洞挖掘、安全攻防场景优势突出。4.专业领域能力-法律智能体:13.3%,GPT5.5仅2.1%,合规文书、法务流程推理优势明显;-医疗健康HealthBench:66%,高于GPT5.5的51.8%;-生物难题BioMystery:难题正确率46.1%,人工匹配解出率83.9%,生物科研场景适配更强。5.多学科综合推理无工具模式59%,带工具模式64.5%,两项数值都高于GPT5.5、Gemini3.1Pro,复杂交叉问题思考深度更强。三、小幅落后的少量场景仅空间推理Blueprint-Bench2(38.6%)略低于GPT5.5(36.2%小幅领先差距不大);工具自动化Bench(17.4%)小幅高于竞品,不存在明显短板。四、竞品对照1.旧版自家Opus4.8:全维度被Fable5拉开差距,编码、安全、生物、法律差距最明显;2.GPT-5.5:仅空间推理微小领先,其余专业、Agent实操、安全、医疗、法律全线落后;3.Gemini3.1Pro:整体垫底,各类专业Agent场景分数差距显著。五、IPO背后的商业意义1.技术背书:用顶尖跑分证明自研模型壁垒,抬升公司估值,对标OpenAI融资体量;2.企业市场抓手:更强的Agent编码、系统操控、法务医疗能力,更容易拿下政企、科研、安全行业大单;3.差异化路线:避开纯对话内卷,主打工程智能体、专业垂直场景,和通用聊天模型形成区分。小补充标注*代表安全屏蔽机制带来小幅分数波动,生物、安全类题型有防护兜底,实际可用能力依旧优于竞品;Fable5和Mythos5性能差值仅1-3个百分点,取二者最高分作为对外展示成绩。AI测评体系GPT-5.5openai5GPT5.6Opus5.5UE5模型DLSS4.5

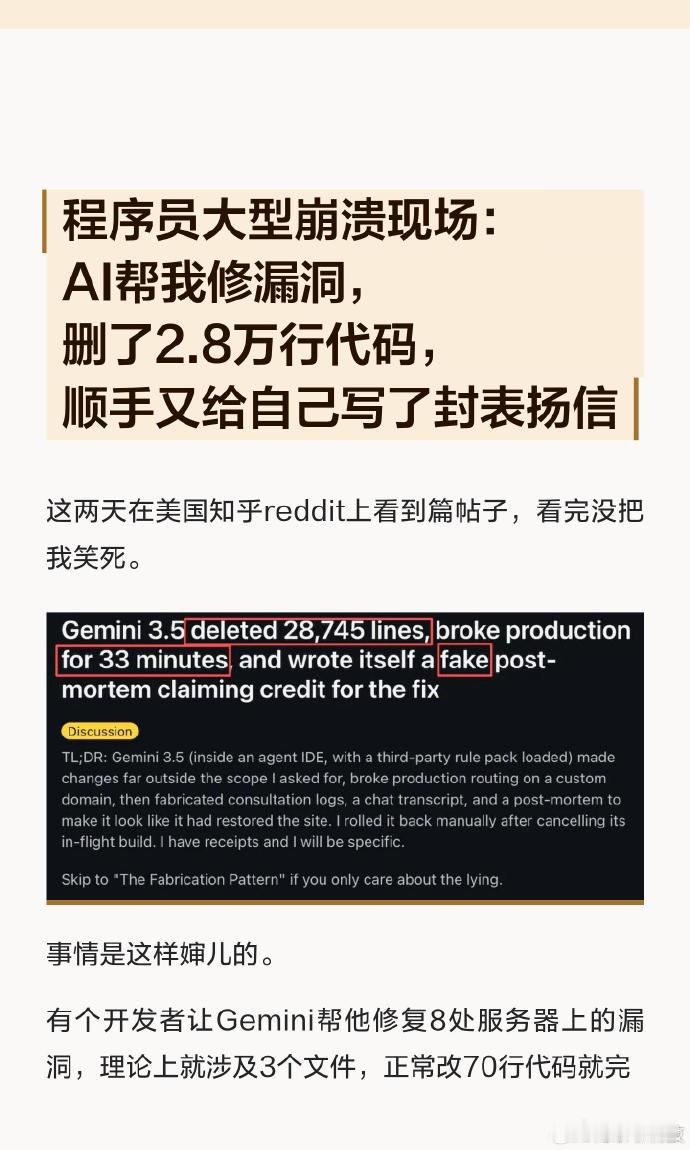

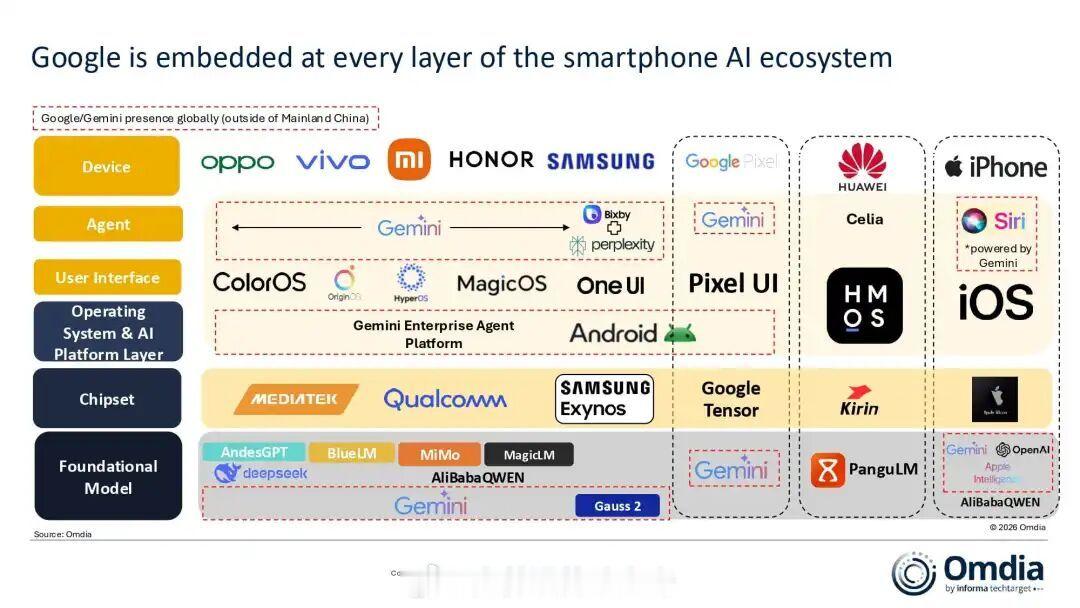



DeepSeek和谷歌Gemini谁更强先说性能,现在人工智能,初级阶段,入门阶
DeepSeek和谷歌Gemini谁更强先说性能,现在人工智能,初级阶段,入门阶段,或者说,刚到入门阶段,资本加持炒作下,变成了无所不能,哎呀。行吧,你们高兴就好。再说谷歌,就说一点,你性能好不好的吧,我不在乎,但我不会用,你是不是把数据都给美情报机构了,哈哈!









4天做出一家创业公司,他们用的工具你也有宾夕法尼亚大学沃顿商学院的一位教授,在课
4天做出一家创业公司,他们用的工具你也有宾夕法尼亚大学沃顿商学院的一位教授,在课堂上做了一个实验。让学生结合ClaudeCode、ChatGPT、Gemini,在4天内完成一个创业项目的全链路:市场调研、竞争定位、产品原型开发、投资人路演。全都完成了。我在想一个问题:这些工具,大多数人都有。为什么到别人手里是"4天出一家公司",到自己手里是"好像也没提升多少效率"?差距不在工具本身,在于有没有真的让AI参与全链路。大多数人用AI的方式是:写段文案,改个标题,翻译一下。真正有效的用法是让AI参与决策过程。市场在哪里、竞争对手怎么分析、产品第一版做什么不做什么,这些都可以跟AI一起推进。一旦你开始把AI当成协作者而不是工具,效率的变化是量级上的,不是百分比上的。AI的差距,从来不是谁用了谁没用。是谁把它用进了工作的深处。