原创:亲爱的数据

月之暗面的Kimi K2.6模型开源了,
我玩了玩,
更加确信一个判断:
别再依赖外界Benchmark,
要有自己评估模型的Benchmark,
也就是自建Benchmark。
比如,一个头部大模型公司的模型开源了,
你必须在半天之内搞清楚,
这个模型强在哪,差在哪。
这是当下企业技术一号位的核心竞争力之一。
如果这点都做不到,
说实话,谭老师都不想和他(她)聊天。
无独有偶,今年年初,
火山引擎内部的一次分享,
我亲耳听到吴迪老师也是这么说的,
当场,想把大腿拍断了,
考虑到以后走路还要用,
就算了。
而且,我还想小声说,
那些唯打榜论的流派,求断更。
我不是说啥Benchmark都不参考,
参考也是行业惯例。
但我还是想说,
即便模型能力是通用的,
业务不是通用的,
你想在某个场景上表现好,
SWE-bench考满分也跟你没关系。
那怎么做呢?
我的想法是把业务场景变成考试题,
你自己出题,拿来考每一个新模型,
"半天之内告诉我强在哪,差在哪"这意味着什么?这话的潜台词是:
自建Benchmark必须是,
自动化的、可复现的、随时能跑的。
而不是,派个手下小弟,
手动试用三天,写一份报告。
而是,一个新模型开源了,
你把模型接入自建测试管道,
按下按钮,测试跑起来,
半小时后,
拿到一份结构化的评估报告:
哪些场景比上一个模型好了
哪些场景退步了,
哪些场景完全不能用。
不是"我能判断模型好不好",
是"我建了一套系统,
能自动判断模型好不好"。
一个是个人经验,一个是组织能力。
孰强孰弱,不用多说。

所以,我从不认为自己在“测评”,
上手玩一圈,说一下手感怎么样,
哪里惊到我了,哪里不太好。
评测给的是结论,体验给的是感受。各有其用。
说回Kimi K2.6,
月之暗面刚开源的这个模型。
圈子里讨论不少,群里聊得也挺热闹。
但别人说好不好用不算数,
自己上手摸一把才算数。
以下是我的体感。
先上一段提示词:

这个执行流程,可以展开一下,
第一,用SKILL。
两次读取 SKILL.md,
按照预设的Skill指导自己一步步做,
不是一开始全加载,
而是做到哪一步才读哪个 Skill。
第二,派出子Agent。
Kimi的Agent集群派了一个设计师西泽。
因为目前只有1个并行任务。
且我的需求只有一个网站,
所以它只派了一个子Agent。
真正的集群压力测试得看,
同时派三五个子Agent 的场景,
后面我会设计一个更难的,
"同时出 Word + Excel + PPT"的任务。


第一眼确实有点东西。
暗色背景、金色分割线、
排版克制,没有满屏霓虹灯的廉价感。
导航栏的分类也算合理,不像是AI随便编的。
但严格讲,标题“AI 代码纪元”,
这种命名还是有股AI味——太宏大,
要我说,写大不难,而写准很难。
整体体验上,视觉90分,内容框架80分,
我的体感是,拿来当快速原型,
用来展示完全够用。
看到这,我突然想到,
以后展示项目成果可以用AI,
这种网站视觉效果可比PPT好多了,
AI编程这么方便,
很多办公软件会直接被干掉了,
如果以后谁还让同事填Excel表,就太老登了。
只玩成这样贴图可不行,
就成AI生图测试了。
Kimi直接部署了:
https://nzknvyjr6h35i.ok.kimi.link/
既然Kimi K2.6生成了代码,
我让它推到GitHub,
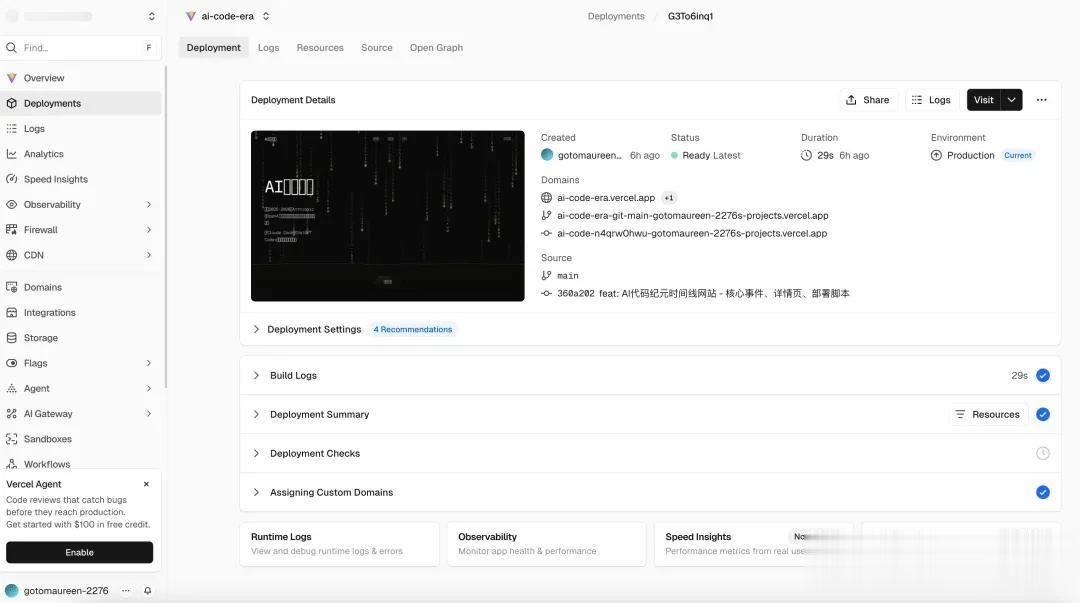
再通过Vercel部署上线一次。
Vercel是“把网站一键发布到互联网上”的平台,
29秒构建完成,状态绿灯,
自动分配了一个域名,
也可以直接公网访问。
https://ai-code-era.vercel.app/
一份代码,两次部署,
工作结束了。
不得不提的是,
再部署的那个备份网址,
用Vercel部署,也是Kimi教我的,
惊不惊喜,意不意外。
我好想说一句,碳基结束了。
几句提示词,
快速拉起一个能打开的网站,
全程没写一行代码,没碰一下服务器,
这个链路跑通了。
能跑起来不报错,
说明K2.6生成的代码质量,
至少过了Vercel这关。
不过,这是静态页面,难度等级一般,
真正的考验是,
带后端和数据库的全栈应用,
也一键跑通,那才是硬仗。
最后,所有的代码都可以直接打包下载,


我和一个技术小哥哥聊天,问他,
这种底座模型迭代,他最想用啥,
他说肯定是Agent集群,
现在的底座模型对Agent友好是“标配”
也就是说,不只是写代码好,
还要在Agent长时间自主运行的场景下,
稳定可靠。
但是,有一点,
当你在Kimi网页端测K2.6的时候,
测的其实是"K2.6 模型
+ Prompt设计,
+ 上下文管理,
+ Agent流程,
+ 工具能力,
这是一整套。
这五层里,大模型只在第一层。
后面四层,全是Harness的事。
Kimi K2.6的Harness的设计原理,现在不清楚,
我们只能用结果说话,
但是,在现在这个阶段,想把Agent集群玩好,
Harness必须杠杠好。

这次关键要看Kimi特有的"Agent集群"能力。
前面讲了,给了三个任务让它同时输出,
“同时”要重读。

这样,要验一件事:
它到底是一个Agent排队做三件事,
还是真的派了三个Agent同时干。
前者是假集群,后者才是真的。
区别不只是快慢,
串行到第三个任务的时候,
Agent的脑子,
已经被前两个任务塞满了,质量会掉。
真正的集群,
每个Agent各管各的,质量稳定。



要知道,体验也是要动脑子的,
我的任务,信息密度都非常高,
CMA是很新的概念,
AI可能会在某个环节,偷懒或降级处理。
关键看它输出的内容里有没有一个细节,
execute(name, input) → string,
这种接口级的信息。
没有,就是泛泛而谈,
有,就是踏实干活。
结果确实被我发现了点端倪:

不过Kimi也很坦诚,
坦诚的前提是智商到位,
否则会死犟不承认,
它明确告诉我:
CMA的API 文档,
execute/handle 方法签名,
Session Persistence 协议细节,
官方架构图,
这些一手信息“我没有,我不瞎写”。
然后,它主动要 URL,
谭老师我给了,它去读了。

大多数AI遇到这种情况,
会怎么做?答案是,硬编。
有些AI,编起瞎话油盐不进。
编一套看起来像那么回事的API接口,
自信满满地交出来。
看似每一步,拼尽全力,
实际每一下,多此一举;
只要不去核实就信了,一用就出错。
然而,K2.6选择了说"我不知道,
让我给官方文档的链接,自己去读。
它知道自己什么不知道,
比起什么都敢编,上了一个境界。
这不是K2.6 "自我纠错能力提升",是啥?
玩到这,是不是觉得手感还不错,
也许K2.6没有想到我会查它的CoT。
哈哈哈,我笑的声音有点大。
要我说,亮点确实有,
但我们还是要让交付结果说话。
我还是要再次强调,
CMA的任务不简单,
我曾经问过10个技术小哥哥,
其中有7个都还没有跟上CMA这波操作。
而那些有实力的大厂Agent团队,
根本不写什么公众号流量稿,瞎吹自己的龙虾,
而是不动声色,打算一鸣惊人。
给大家看个聊天记录,头像已打码。

看看这位小哥哥的微信回复时间,凌晨3:10,
看来,这位大厂同学的刻苦程度,
在我之上,在下佩服。
聊回K 2.6的结果,
我主要看PPT质量
Word和Excel都不重点关注,
主要看子Agent并行情况。

没二话,这页PPT就是我想说的,一图顶千字:
还细心地给我加上了logo,
产品细节到位,好感度+1。

这些都还不够,要更深入,
因为我最喜欢的游戏就是“深入浅出”,

四个维度的拆解是对的。
Agent创业公司、云厂商、企业客户、开源生态,
CMA对这四类玩家的影响确实不一样,
它没有笼统地说"CMA改变了一切",
而是分角色讲影响。
每个卡片的结论有判断力。
不是在陈述事实,是在做推断,
这些结论不是废话,有观点。
底部投资启示那段话写得不错,不是空话。
"模型层的差异化正在减弱,
基础设施层和平台层将成为新的价值高地",
这也是我认同的:
"从卖模型到卖平台"的战略转轨。
写错的地方是:
第一个卡片说,
"CMA直接吸收了 LangChain,
CrewAI 等创业公司的价值主张",
这个说法不够准确。
CMA不是在做LangChain和CrewAI做的事。
LangChain做的是框架,
CrewAI做的是多Agent编排,
"纠缠软件"是什么?Agent?还是Harness?
CMA做的是meta-harness。
CMA没有"吸收"它们,
是把它们变成了可以在CMA 上面跑的应用。
关系是"平台容纳",不是"平台替代"。
CMA是全球领先的新概念,
我出的题目挺难的,
这结果比大多数AI或者人类做的强不少。
AI这么努力的提高自己,
人类也不能躺平。
于是,谭老师我,单方面宣布,
我和那些好用AI的友谊,
青山不改,
绿水长流。