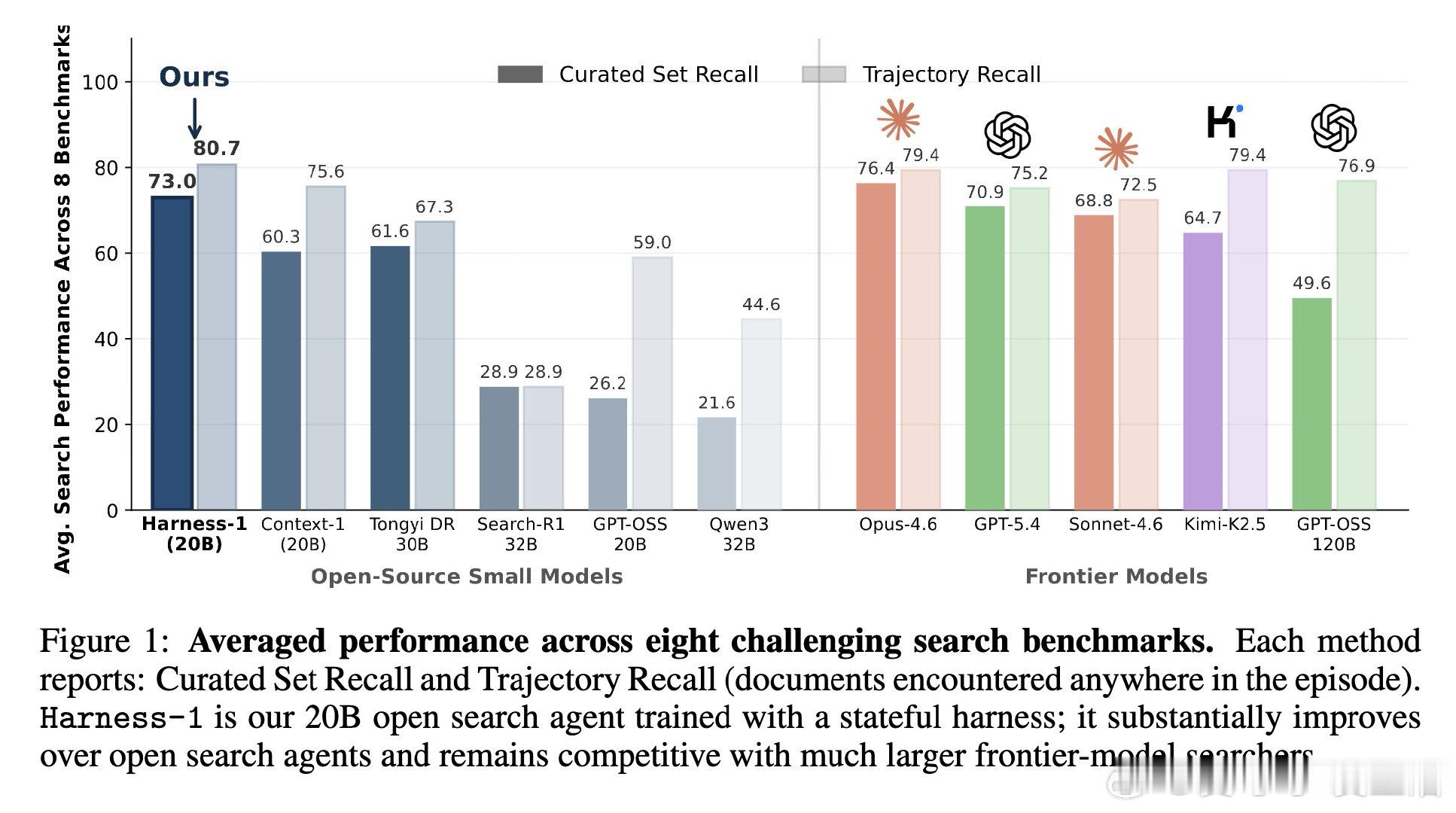
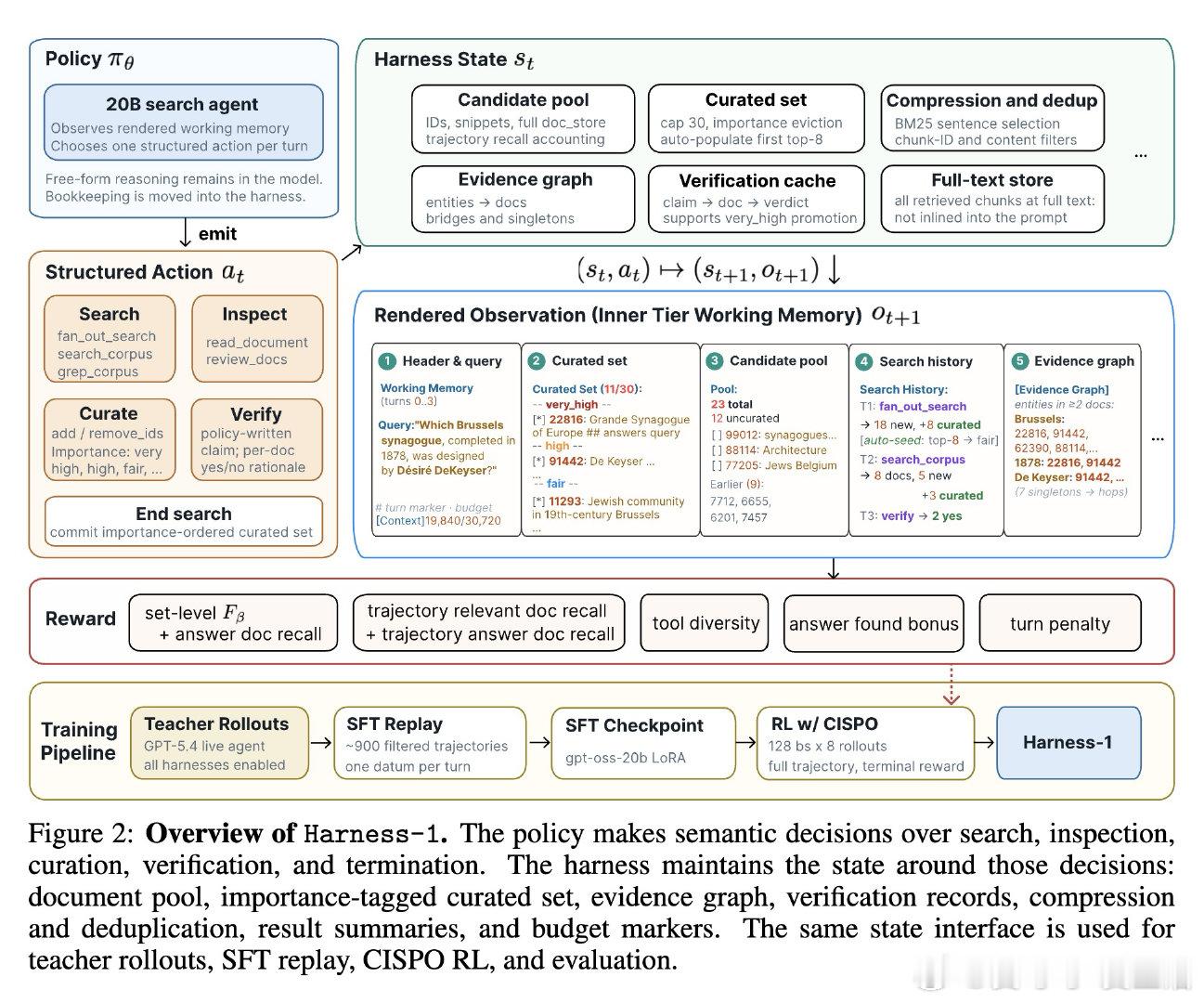
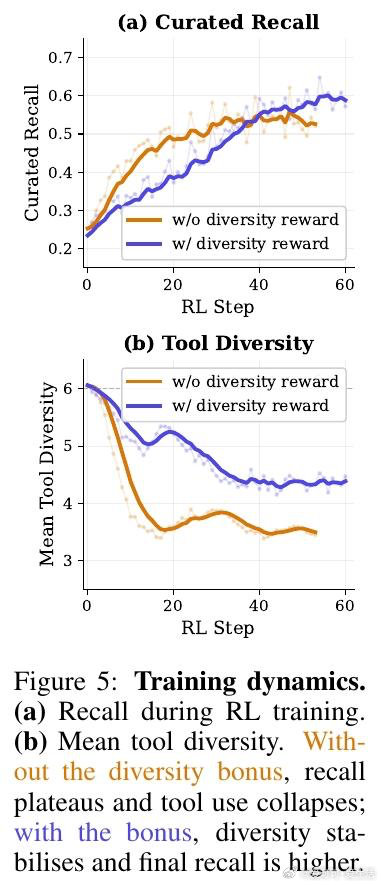
[LG]《Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses》P Jiang, Z Shi, K Hong, X Xu… [University of Illinois at Urbana-Champaign & UC Berkeley] (2026)
在音频智能领域,AUDIO-INTERACTION 面临的核心困境是:现有 LALMs 只能离线处理整段音频或处理单一流式任务,无法像人类一样边听边做判断。其本质问题是模型缺乏对实时上下文的感知与决策机制。
本文的核心突破是将音频理解建模为“感知—决策—回应”的连续循环。通过逐块判断是否回应,模型能够在同一个框架下同时实现实时转写、语音翻译、对话交流和主动干预,使流式音频交互成为可能。
这项工作的价值在于,它将音频智能从“事后反应”升级为“持续在场”的交互模式,为统一流式音频处理打开新路径,同时也揭示了现实噪声环境下误触发仍需优化的挑战。
arxiv.org/abs/2606.02373 机器学习 人工智能 论文 AI创造营