[AS]《Audio Interaction Model》Z Xie, Z Liu, Z An, X Hu… [NTU & NUS] (2026)
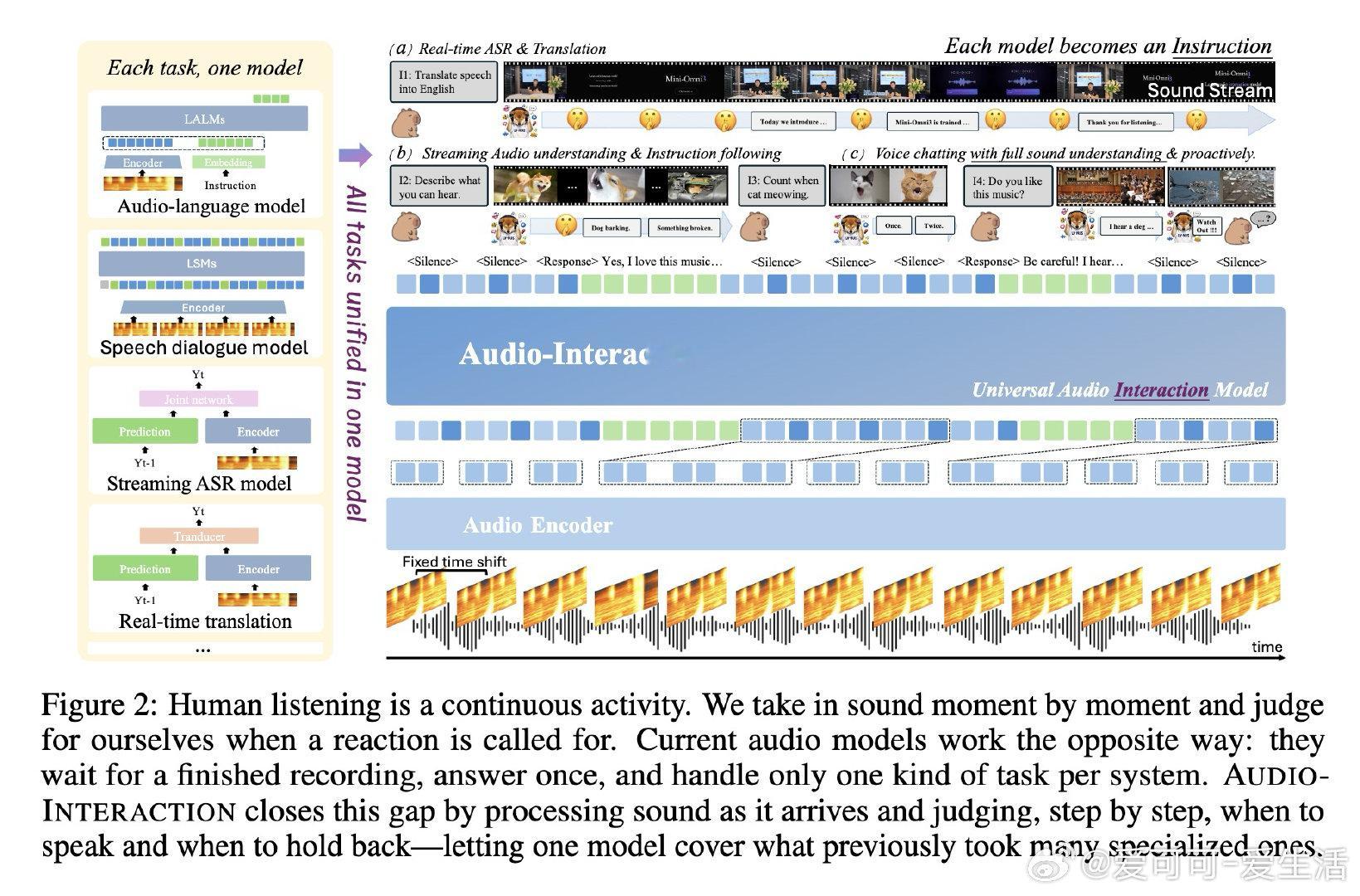
在音频智能领域,实时互动是一个悬而未决的难题。过去的方法受困于离线整段输入或单任务流式模型,本质原因是模型不会边听边判断何时开口。
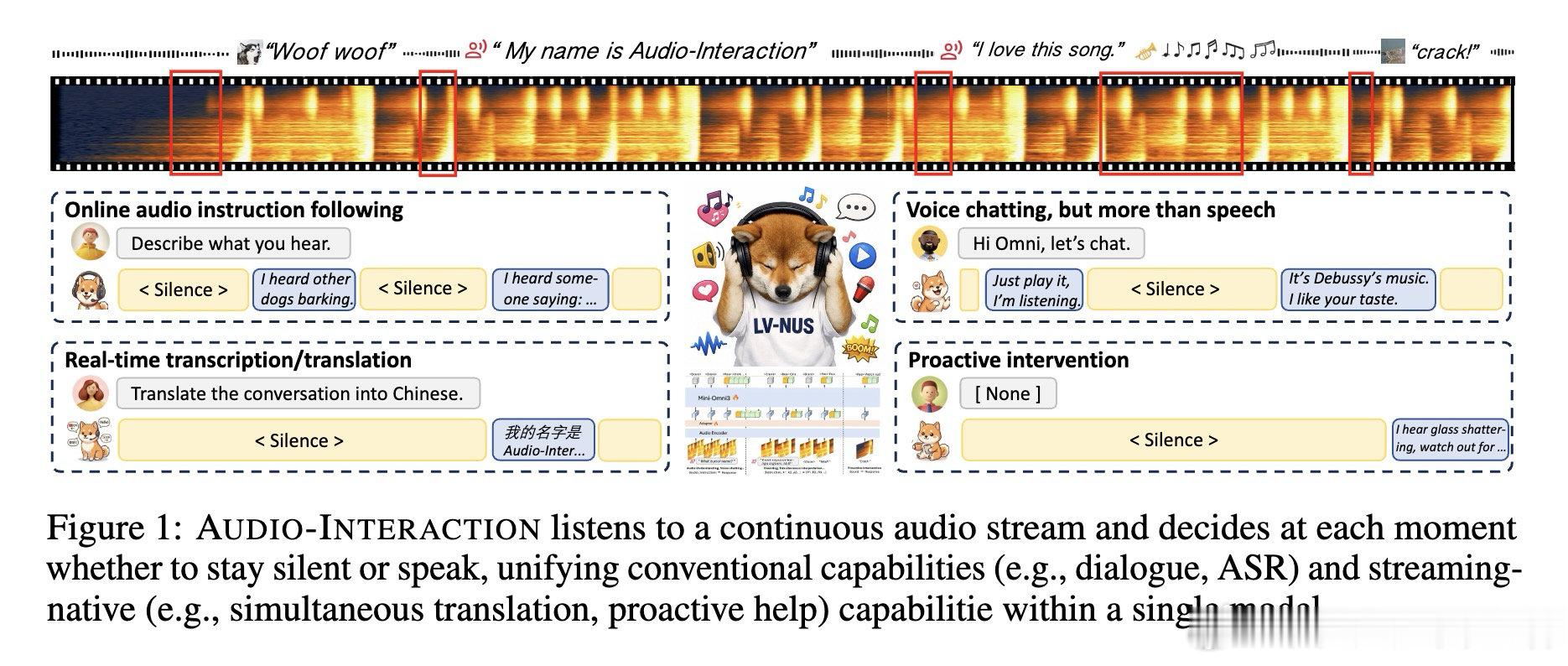
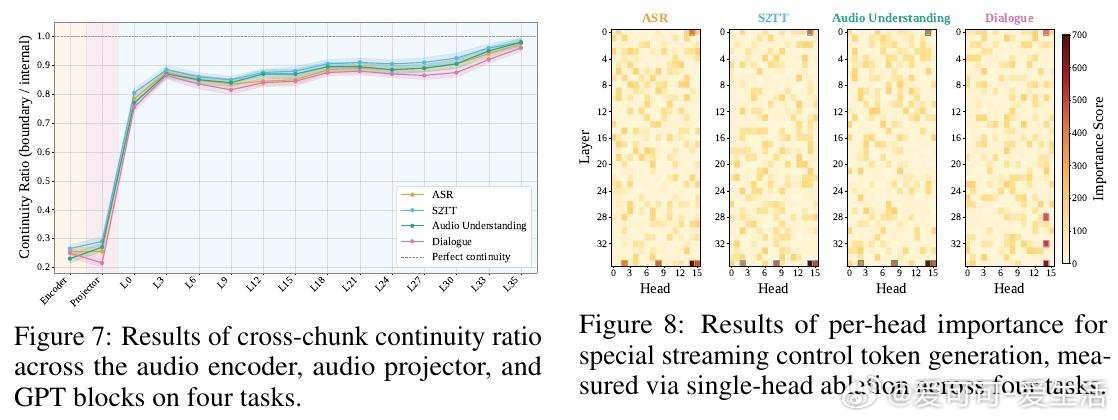
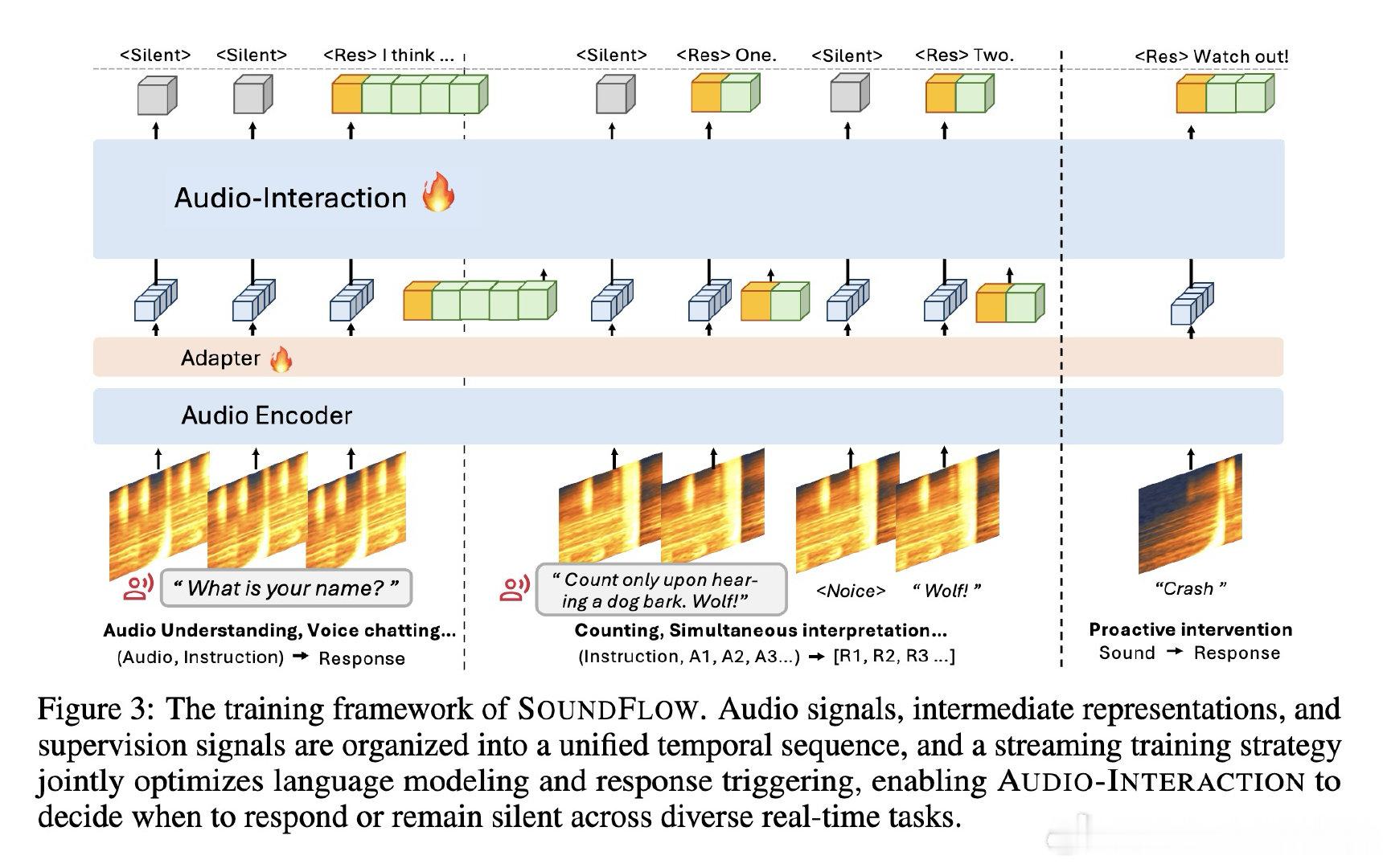
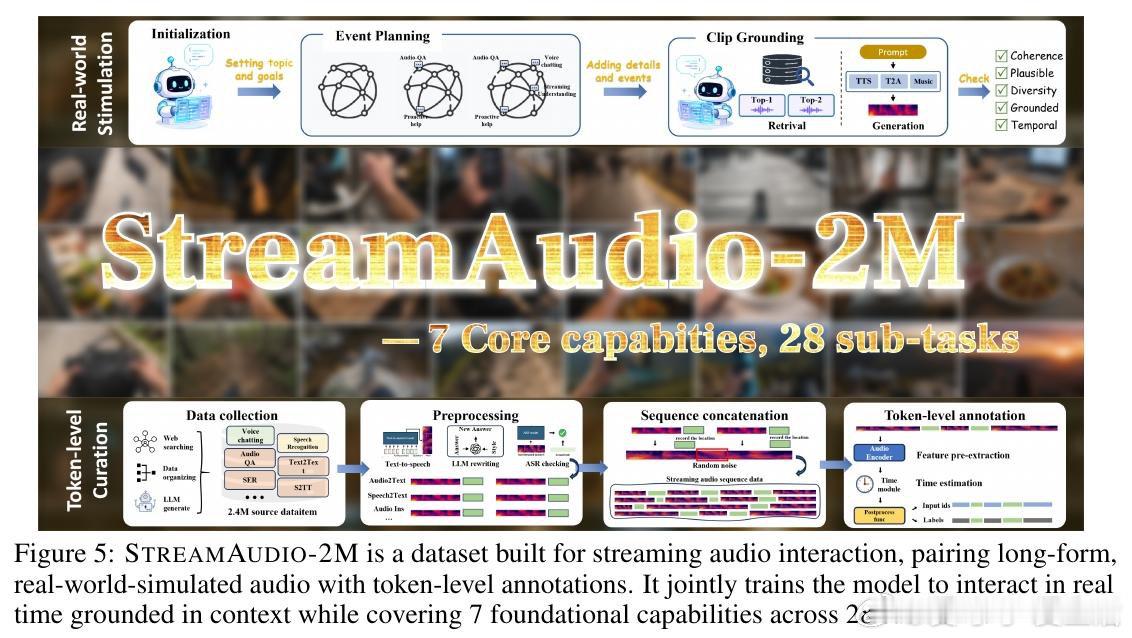
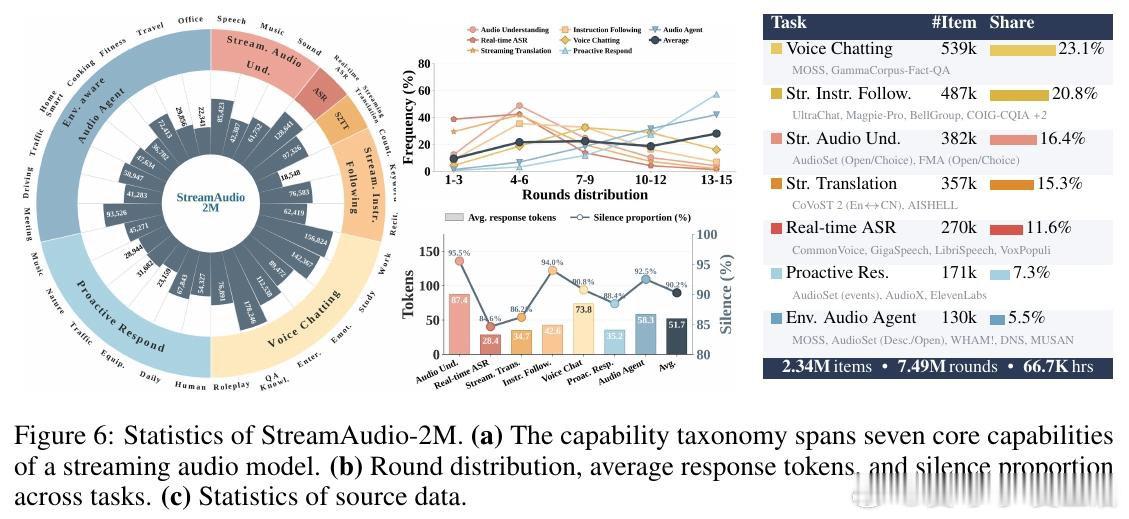
本文的核心洞见是:把音频理解重新看作“感知—决策—回应”的连续循环。由此,逐块预测沉默或回应这一关键操作使实时指令、转写、对话和主动提醒得以统一。
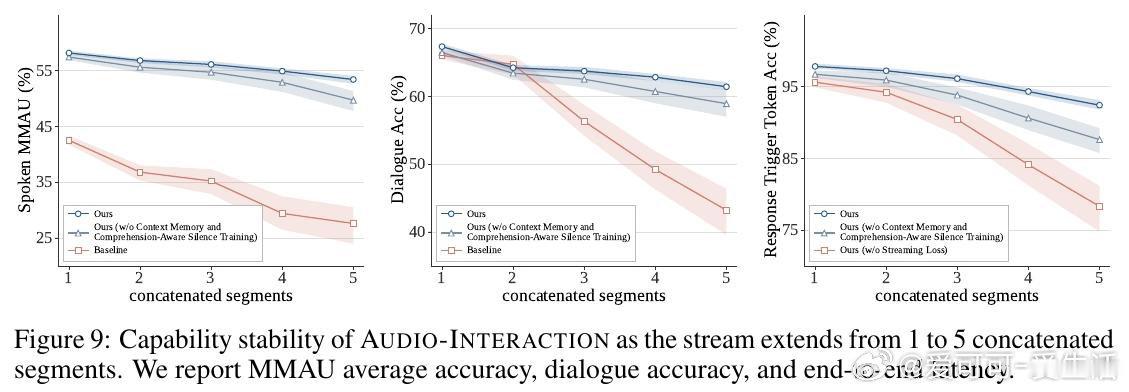
这项工作真正留下的遗产是让音频模型从“听完再答”转向“持续在场”。它为后来者打开的新门是统一流式音频智能,但尚未跨过的门槛是真实嘈杂场景下的误触发。
arxiv.org/abs/2606.05121 机器学习 人工智能 论文 AI创造营