从编程角度介绍大模型应用(4):深度研究(Deep Resarch)的过程
第一节:从编程角度介绍大模型应用 网页链接第二节:大模型聊天框怎么运作的 网页链接第三节:“联网搜索”RAG的过程 网页链接
即使用联网搜索RAG,大模型也经常犯错。RAG只是简单地去互联网上搜索摘要汇总,一次性根据它生成回答,真假难辩。
人去搜索网上信息,查一次之后会再去搜索别的信息印证,有时还计算器算下数字。这个原理把它扩展,就是“深度研究”(Deep Research)。对一个主题,AI反复搜索,最后写出十几页的深度报告,信息质量比聊天框好多了。没用过这个功能的朋友建议去试试,有些要付费,绝对值。买股票时让AI深度研究下都好多了,比聊天框里问股票信息强。
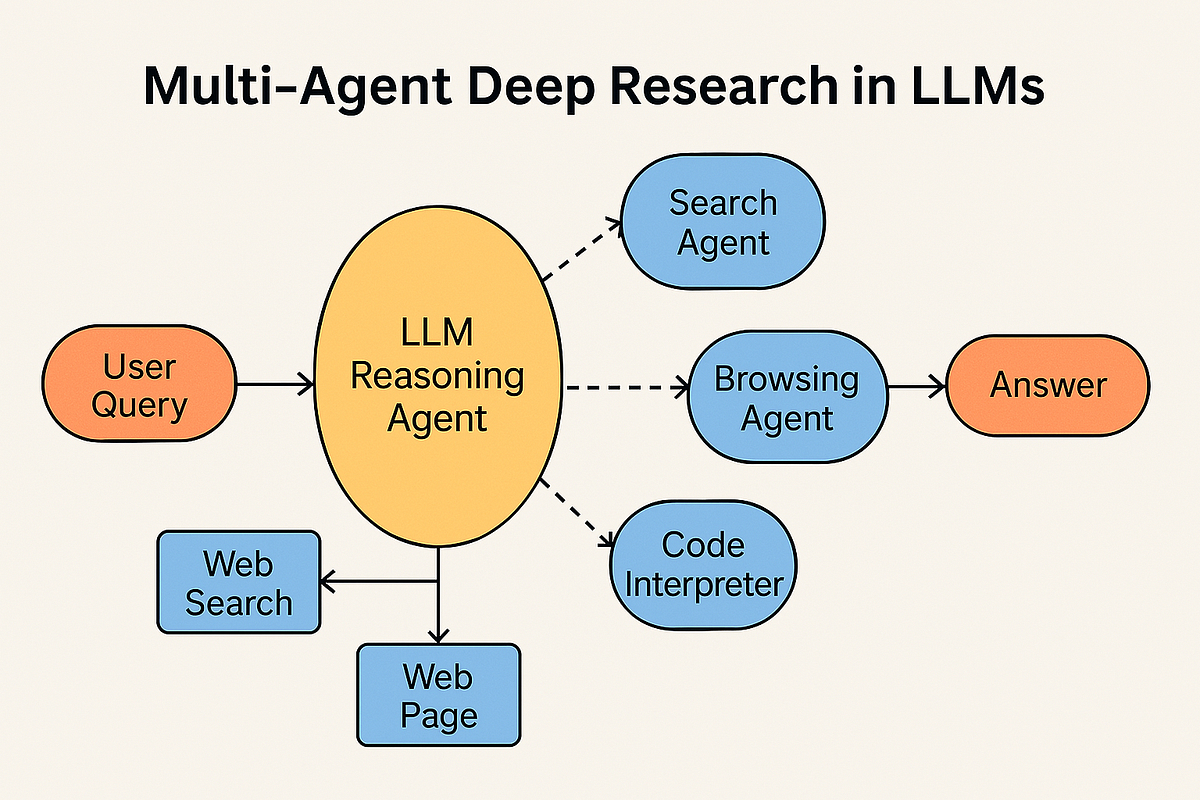
深度调研本质上是一个多轮Agent工作流,以前没Agent概念时,OpenAI就鼓吹说Deep Research多厉害,就是最早的Agent应用。
深度研究最显著的不同,是要开“虚拟机”。要搞5~20次网络搜索,迭代进行;对网页要读全文、做笔记、交叉验证、发现矛盾;除了搜索,还有浏览、写代码执行、文件读写;输出不是几段话,而是结构化的长报告;调用模型几十次,推理、搜索、写作、反思。这必须在隔离环境里进行,需要虚拟机,保证安全浏览与抓取,防止恶意网页攻击后端。代码执行与数据分析也需要虚拟机,写程序编译执行。代码在虚拟机里运行死循环了、乱删文件,也只是沙盒里,不会出大事。还有大量中间文件,虚拟机能提供临时文件系统。
深度研究调用几十次大模型,有非常详细的任务规划,3-5轮大循环,每轮里多次小调用。如第一轮是规划与分解,先读用户问题,写出“调研计划”,如“这个问题需要查市场规模、主要玩家、技术路线”,输出一个待办清单(To-do List)。这要有意对大模型训练,才有这个能力。
第二轮是并行搜索与阅读,对每个子任务发搜索请求(并行进行),读返回的网页,模型提取关键信息,写笔记,这里用轻量级模型做信息抽取。
第三轮是反思与补漏,调用大模型检查收集的信息,发现缺口。如“技术路线只有 2023年的数据,要搜2025年最新进展”,就去针对缺口再次搜索、阅读。这个功能也是训练出来的。
第四轮是整合与验证,调用模型交叉验证不同来源信息,标记矛盾点。对矛盾点再次搜索确认,重复前面的步骤。
第五轮是撰写报告。调用大模型让写大纲,再调用它写引言、正文、结论,再调用它统一润色、检查格式。观察深度调研干活实时输出,是能看到实时在写。
一次深度调研可能有20~50次模型调用,推理、搜索、写作。整个过程跑完要好几分钟,复杂的要半小时。
上面的过程,是一个特别写的深度调研程序,叫编排层(Orchestrator),或者叫Agent Loop或Research Agent。不是随便设计的,有学术背景,叫ReAct(Reasoning + Acting)架构。ReAct是2023年普林斯顿和谷歌论文《Synergizing Reasoning and Acting in Language Models》提出的。
这套办法先做工具定义(Tools),告诉模型它能调用哪些工具,如搜索、浏览器、Python、计算器等等。再来提示词工程(Prompt Engineering),给模型设定“调研员”角色,规定输出格式。还有状态管理(State),维护调研进度、已收集的笔记、待办清单。还要有容错机制,搜索失败时重试、网页打不开时换来源、代码报错时自动改代码。
流程说起来挺自然,第一步干啥,第二步干啥,细节并不简单。过程有分支,下面干什么要思考判断,不是简单的直线执行。ReAct就是让大模型“一边想,一边干,看了结果再接着想”,把原来一次性的“输入产生输出”,用工程的办法变成了“思考、行动、观察”。
细节是,大模型其实只会输出token,并不是真的在思考“下一步干什么”。是开发者有意训练大模型,让它看见特殊的prompt组合,就写一段“内心独白”,再说“选这个工具调用”,任务还是输出token。真正能执行的是系统,但系统不会思考,看到独白和工具选择,就照着执行。系统很笨,看不懂大模型的自然语言独白和工具选择。要训练大模型输出特别的格式,如JSON Schema,系统就能简单解析。
深度调研很复杂,要并行做事,要反思,是不简单的Agent程序,写好不容易。看看深度调研是如何做的,大模型编程开发的特性就能懂一些了。开发者很能想招,把很复杂的Agent程序都做出来了,需要训练大模型配合一些步骤。
深度研究调用大模型次数不是太多,消耗token不是太多,几十万token不是太多。下面介绍消耗token非常多的Agent程序。