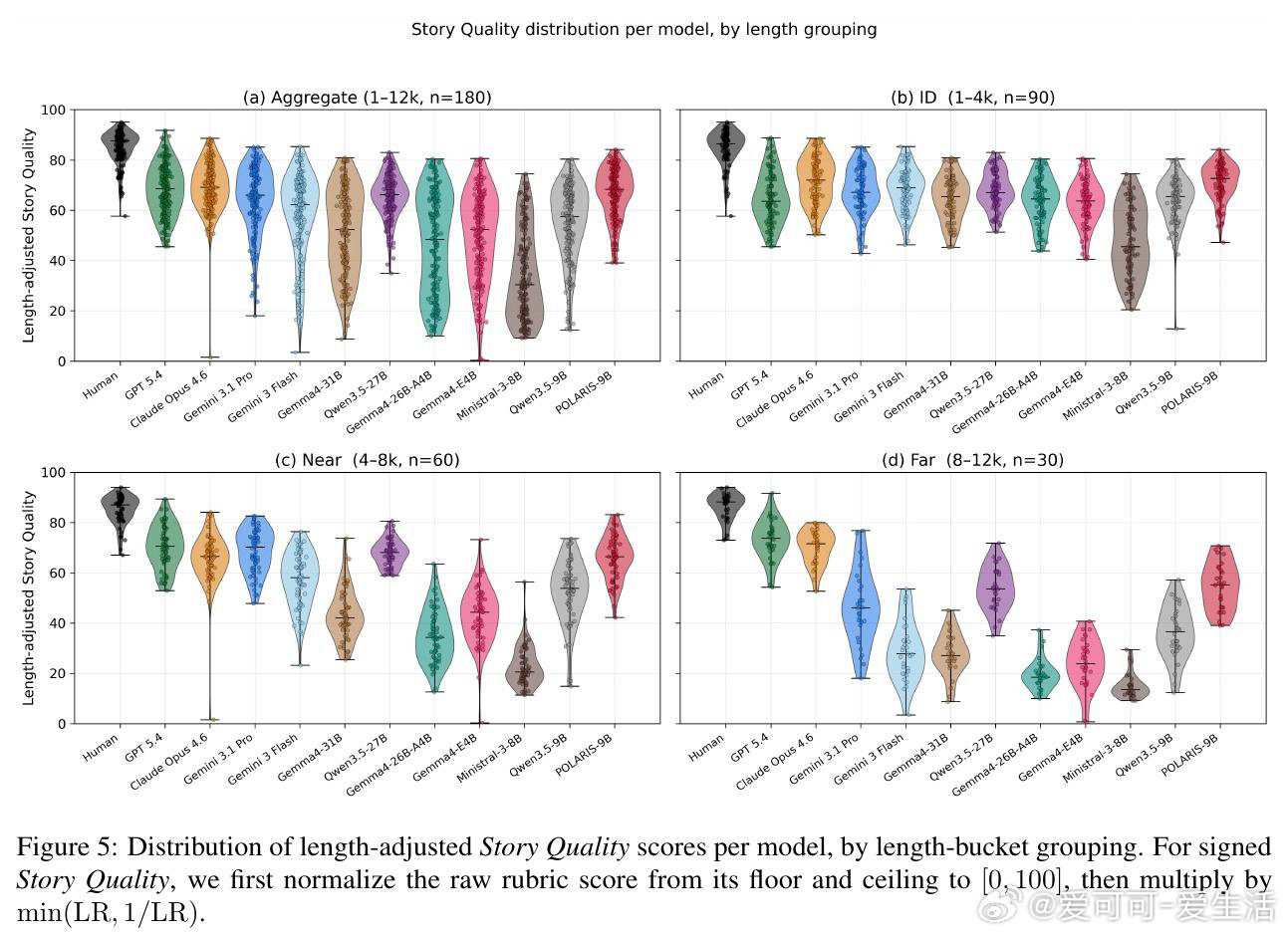
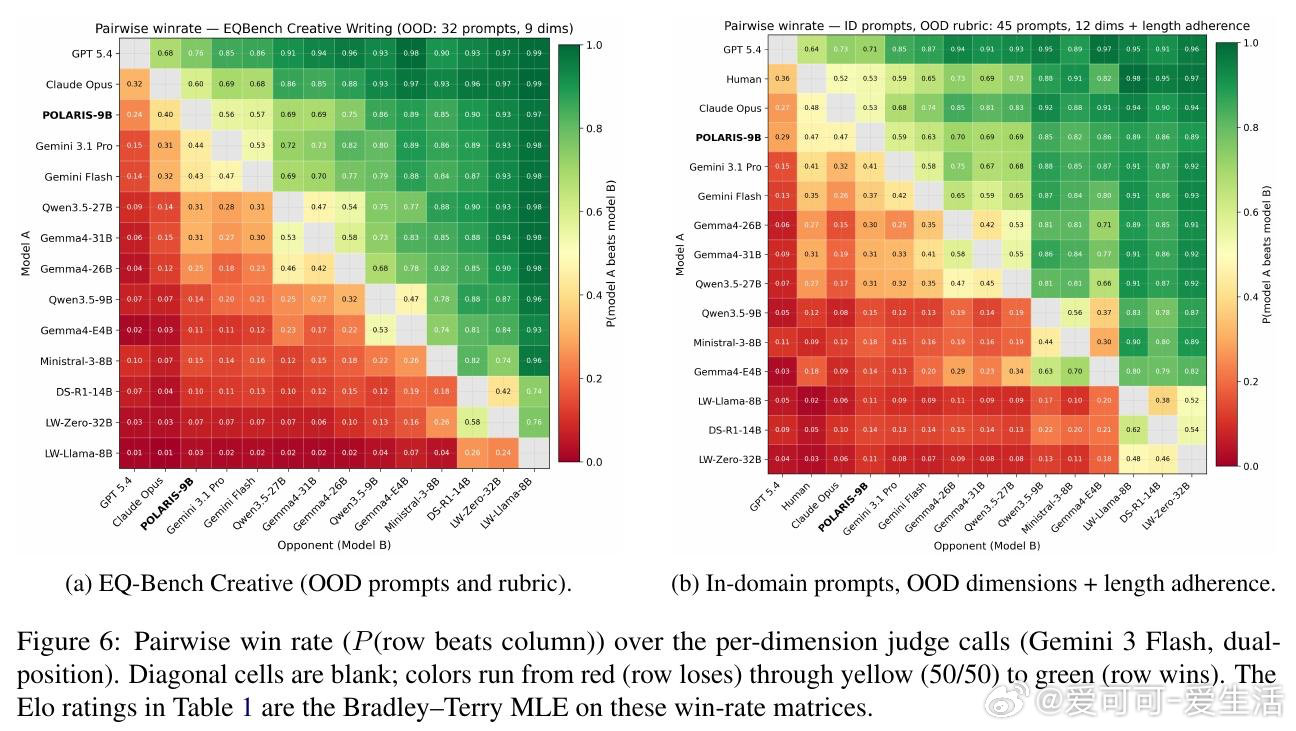
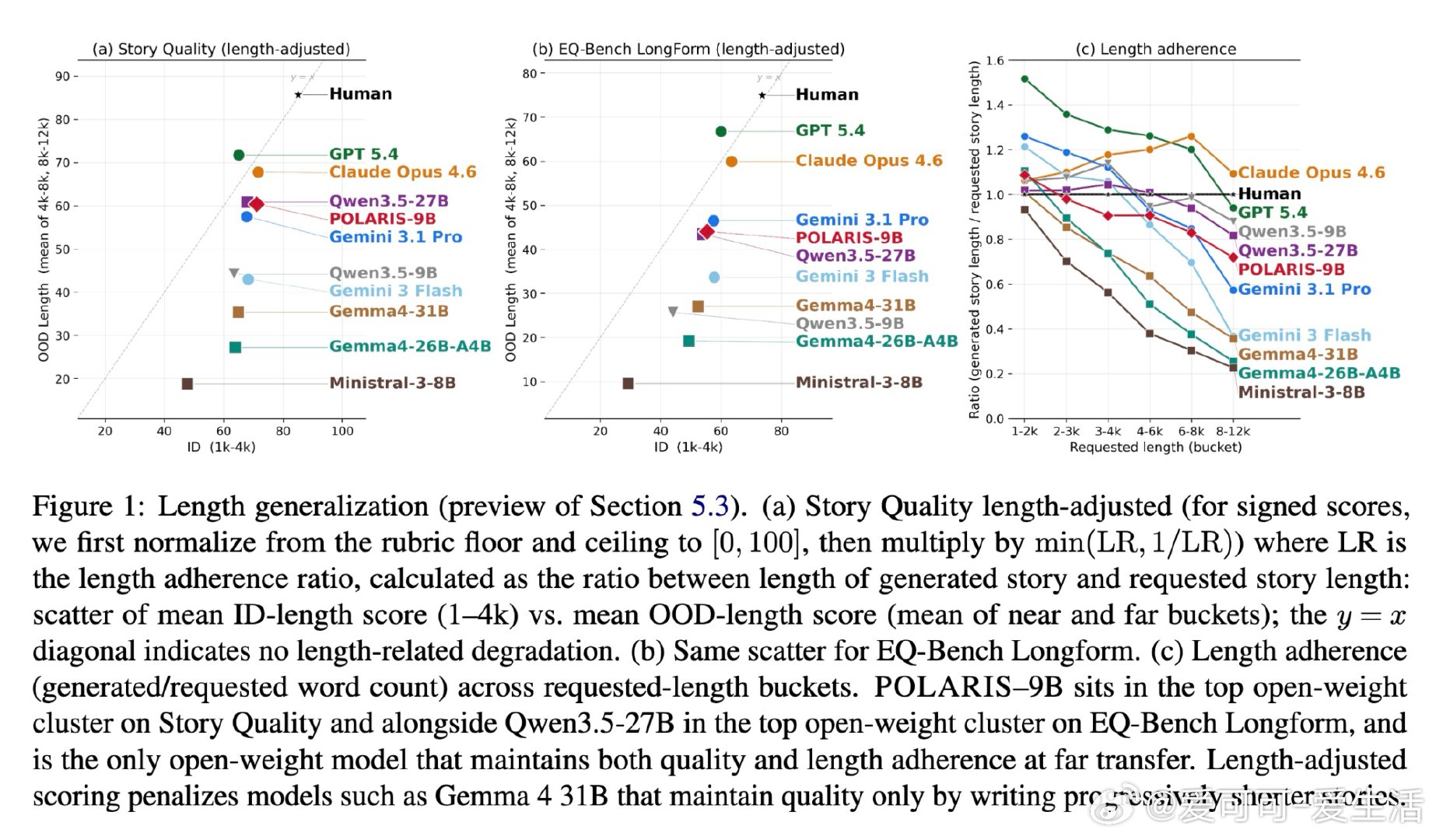
[CL]《POLARIS: Guiding Small Models to Write Long Stories》R Rajendhran, J Russell, M Iyyer, J F Wieting [University of Maryland & Google DeepMind] (2026)
在小模型长篇创作中,字数一拉长,故事要么写不够,要么质量塌陷。过去方法依赖大模型、海量数据或专门奖励模型,本质是把开放写作硬塞进昂贵的偏好训练管线。
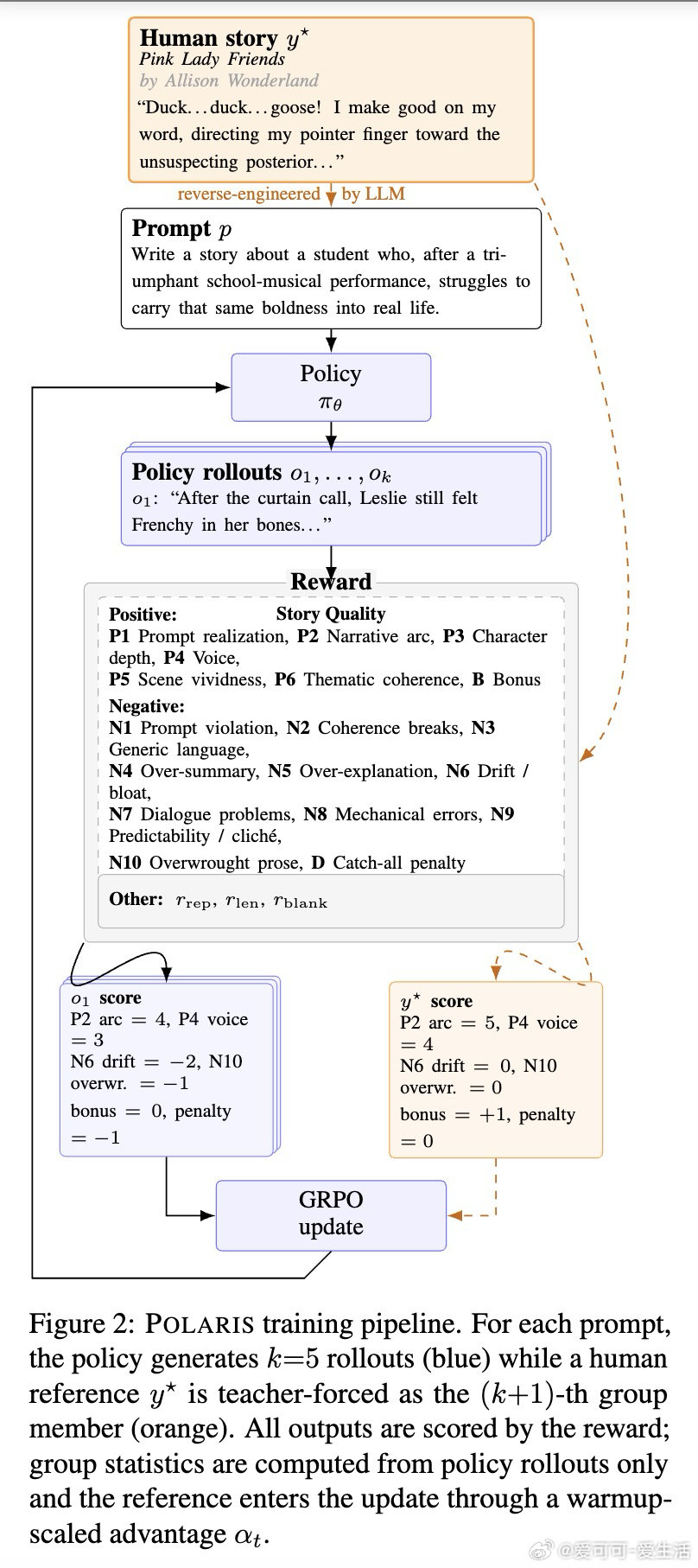
本文的核心洞见是:把长篇写作训练重新看作“有锚点的在线评审”。由此,LLM评委给出分维度奖励,人类故事被注入GRPO组内作高分参照,持续拉住模型向好故事靠近。
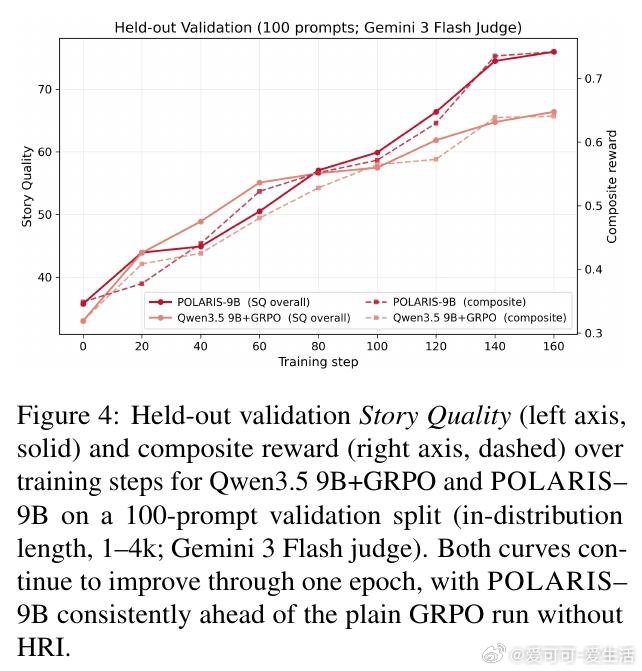
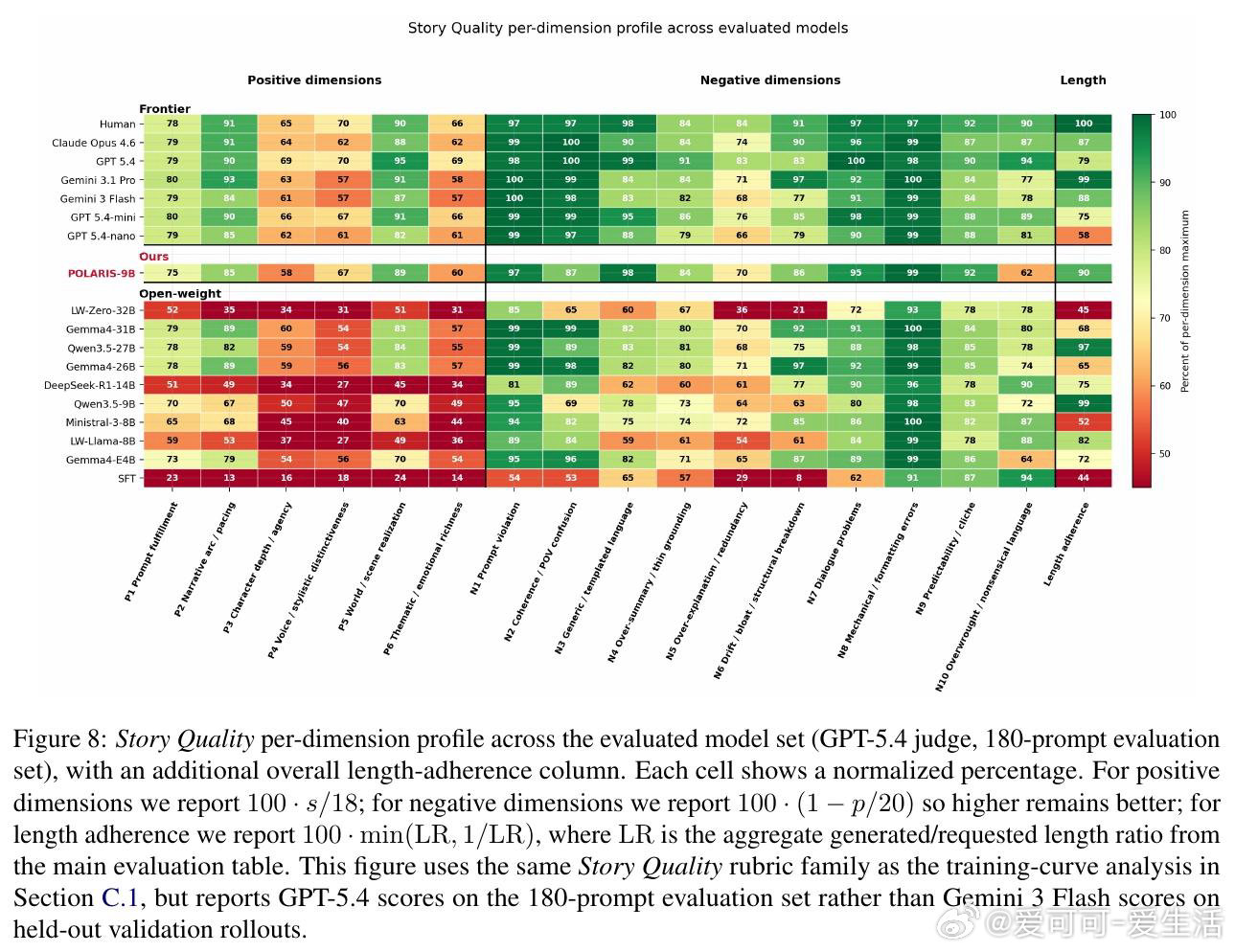
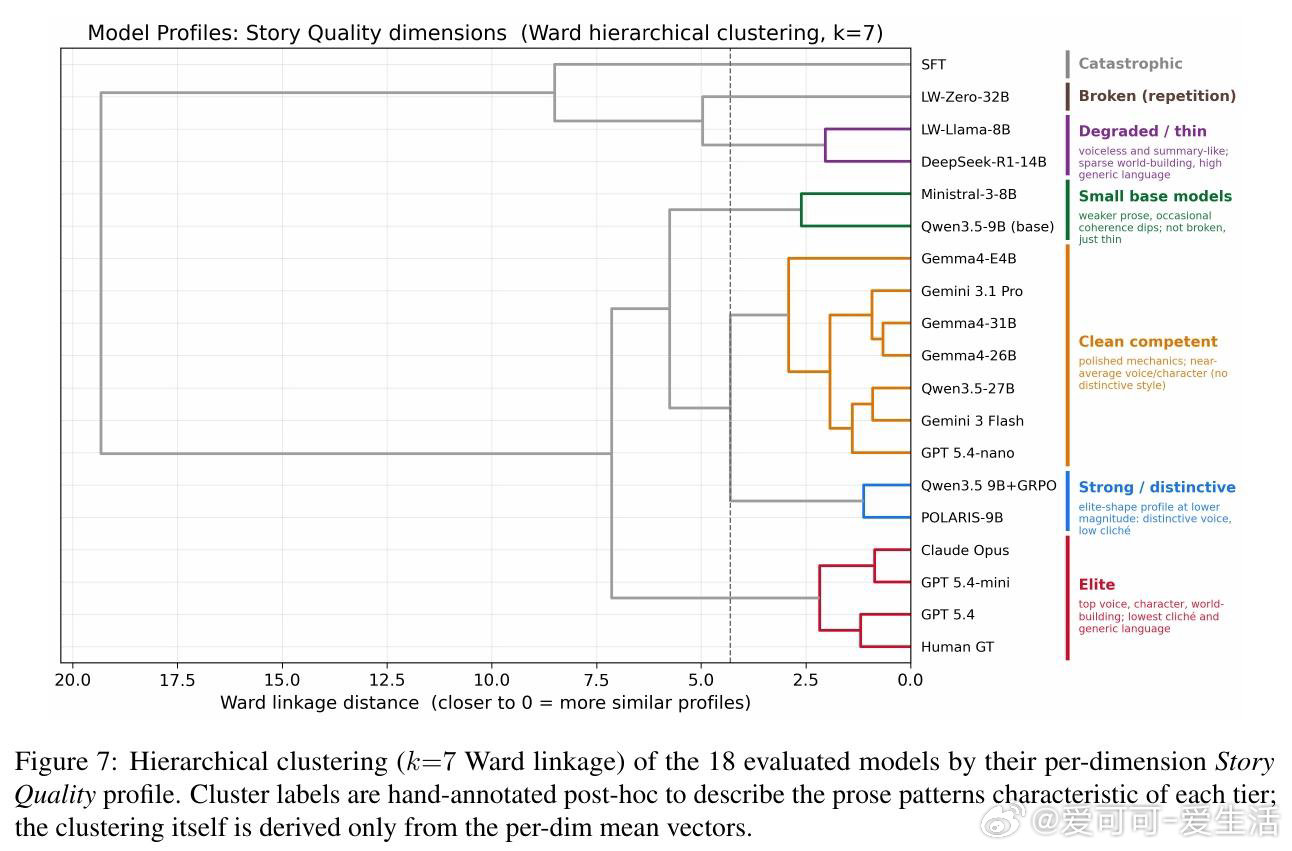
这项工作真正留下的遗产是证明9B模型也能学会较长故事的结构耐力。它打开了低算力创意RL的新门,但尚未跨过的门槛是评委偏好、版权数据与8–12k字长度欠写。
arxiv.org/abs/2606.04095 机器学习 人工智能 论文 AI创造营