从编程角度介绍大模型应用(3):“联网搜索”RAG的过程
第一节:从编程角度介绍大模型应用 网页链接第二节:大模型聊天框怎么运作的 网页链接
一开始大模型聊天就是纯聊,没有搜索。所以大模型的“知识”有个截止时间,之后的事就不知道了。这搞得幻觉一堆,非常不靠谱。
后来聊天框有了个“联网搜索”的按钮,点上它,大模型先会去网上搜相关知识再聊,幻觉少多了。一些人不知道这个模式,用得莫名其妙。联网搜索很有必要,我是必然打开的,感觉不对劲就去看是不是纯聊没搜索。但后来发现,聊天框已经没这个选项了,会自动判断。
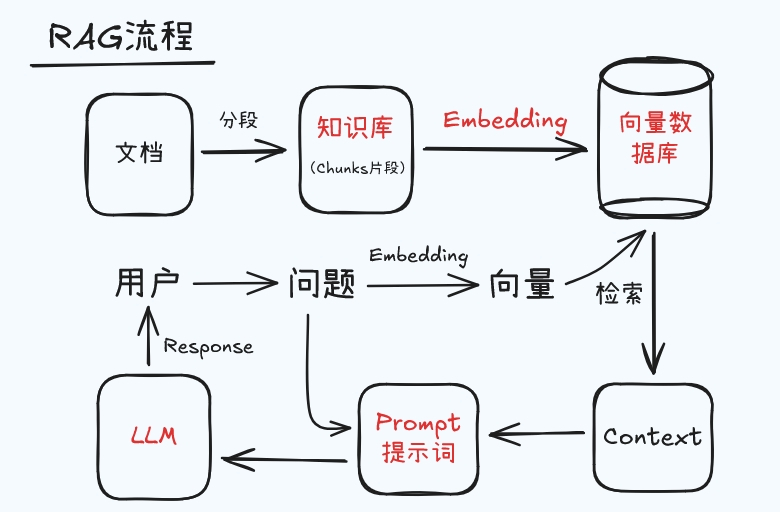
从技术角度看,联网搜索需要的编程能力,远比纯聊天程序多。大模型放在那供调用,纯聊天编程需要的是上下文拼接生成输入矩阵,听上去不难。联网搜索对应学术概念RAG(Retrieval Augmented Generation,检索增强生成),有不少技术细节,不简单。
概念上联网搜索就是去网上找资料,和上下文、prompt一起发给大模型。系统先要判断,“帮我写首诗”不需要搜,“今天的股价”要搜。这步就不简单,需要智能。
一般会用轻量级系统程序快速过滤,再由大模型二次判断。轻量级系统会看关键词,今天、最新之类的要搜,还有正则表达式之类的规则组合,是字符串处理技术。显然,这种传统程序算法智能很差。要专门训练一个专用小模型来判断,或者直接用基座大模型来判断,先问大模型“客户说了XXXX,要不要搜”,但效率低。先快速把需要搜的找出来,找不出再问小模型大模型,混合判断,基本就可以了。也有不管什么输入都搜的。
判断要搜索了,困难才刚开始。拿什么关键词搜?用户输入的一堆话里,什么才是要搜的?这步叫“查询改写”(Query Rewriting),把用户输入,改变成查询用语。这必须用大模型、小模型(可以和前面那个判断小模型是同一个)来干,专门训练这方面的任务,人写程序逻辑根本不行。例如客户第一轮问,“介绍下A院士”,过几轮问“他最近有什么新论文?”,专用的小模型结合输入历史,改写成查询词“A院士 2026年 最新论文"(查询词有时会显示在聊天框中,人能看到)。这就是大模型系统开发的特点,结合实际业务需要,需要训练很多种任务,不具体干想不到有这么多要训的。
有了查询词,系统会调用搜索引擎或特别的RAG管道,返回100个之类的网页摘要,这一步有标准接口,不难。但不能把所有搜索给果都加入prompt扔给大模型聊天,效率太低,要先找出5-10个靠谱的结果。
结果返回后先“去重”,链接一样的扔掉、标题相似的合并、正文雷同的合并,“相似雷同”程度用传统文本算法处理就可以,如哈希算法。再判断相关性,不太相关的不要,这也是传统算法,计算用户查询向量与文档向量的距离。这两步都是粗排,不是很靠谱。 精排阶段(Reranking)用专用神经网络或者小模型来做,从100个候选精挑出5-10个真正给大模型看。这都是有专门研究的,文档相关性训练,如Cross-encoder把查询和文档拼在一起,模型输出相关性分数。也有用轻量级LLM来做的。
最后,系统会把查询结果和前面聊的、当前prompt拼接,要有截断处理,控制总输入不要太长(太长扔掉一些查询结果),每个查询结果也不要太长。最后就生成了很长的输入矩阵,交给大模型去推理,聊天的结果就靠谱多了。
有搜索聊天就会慢不少,一个是联网搜索本身要耗时,二是搜索来的信息多,KV Cache都会增大不少,加入新的输入计算代价不小。明显比纯聊天慢,经常“转圈圈”。
从联网搜索就能看出来,大模型应用想做好不简单,并不是训练好一个基座大模型就行,还得配合开发不少小模型和传统代码。
联网搜索聊天,由于网页信息经常有错,所以有时也不是太靠谱。更靠谱的是“深度研究”,下一节介绍它是怎么做的。