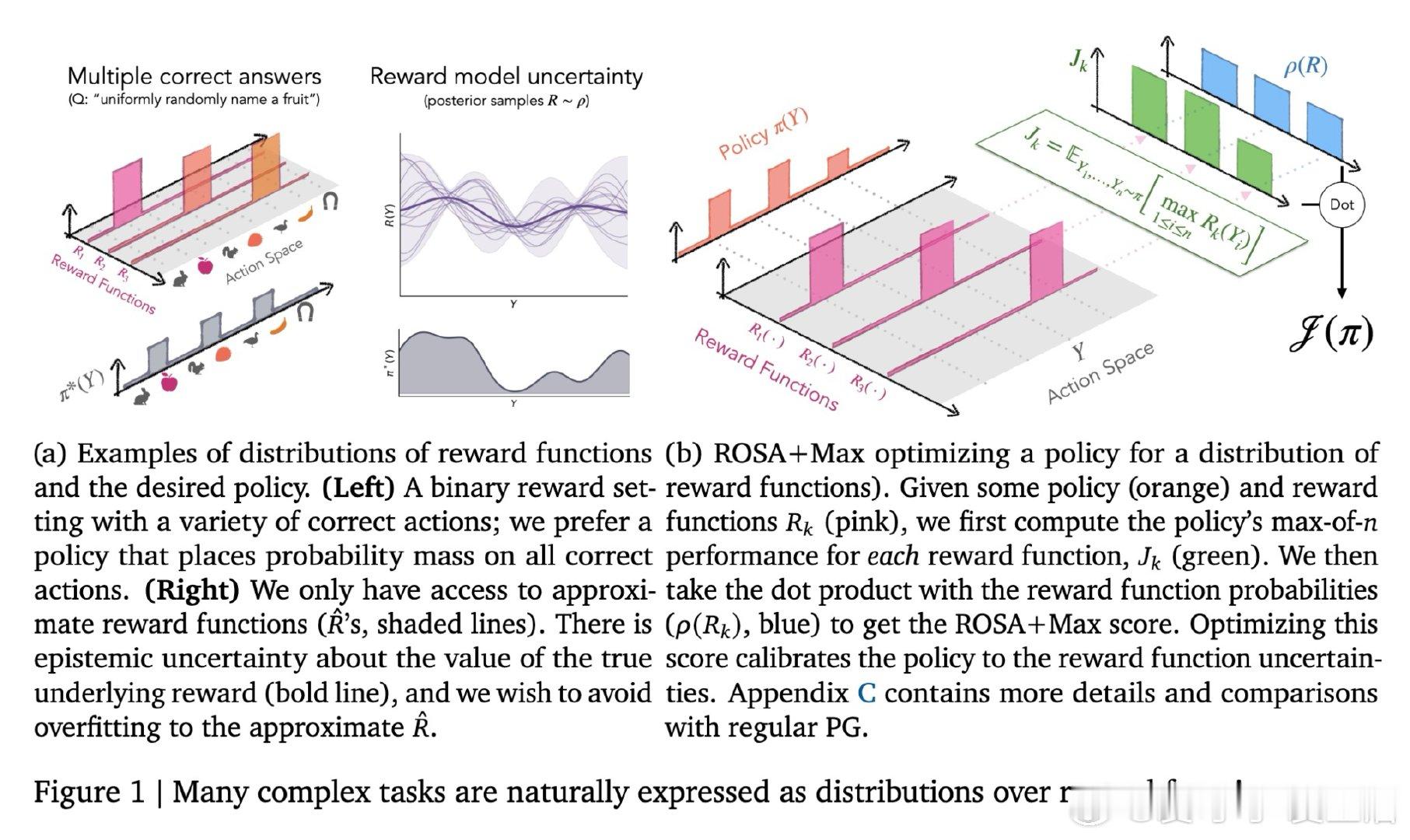
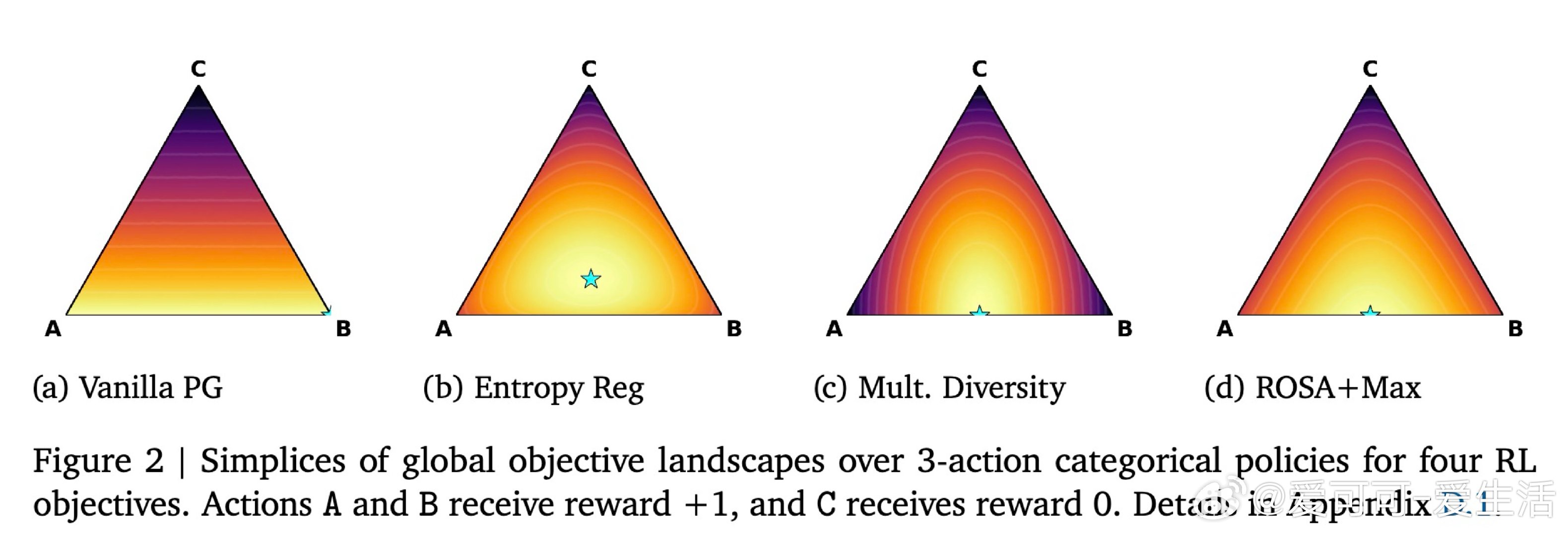
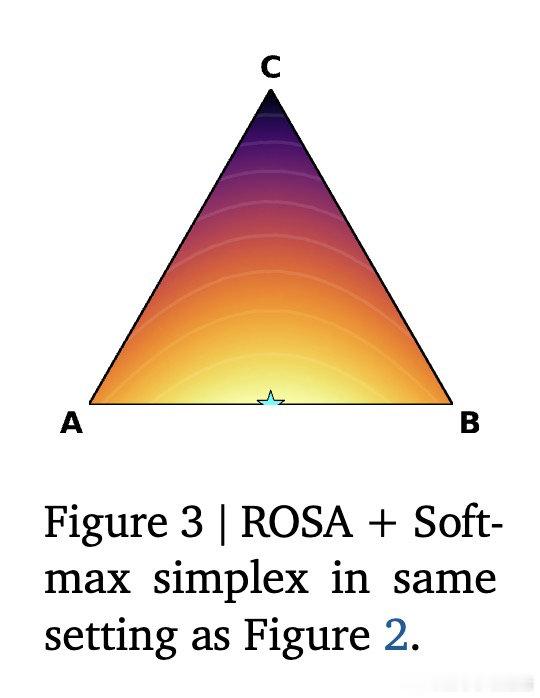
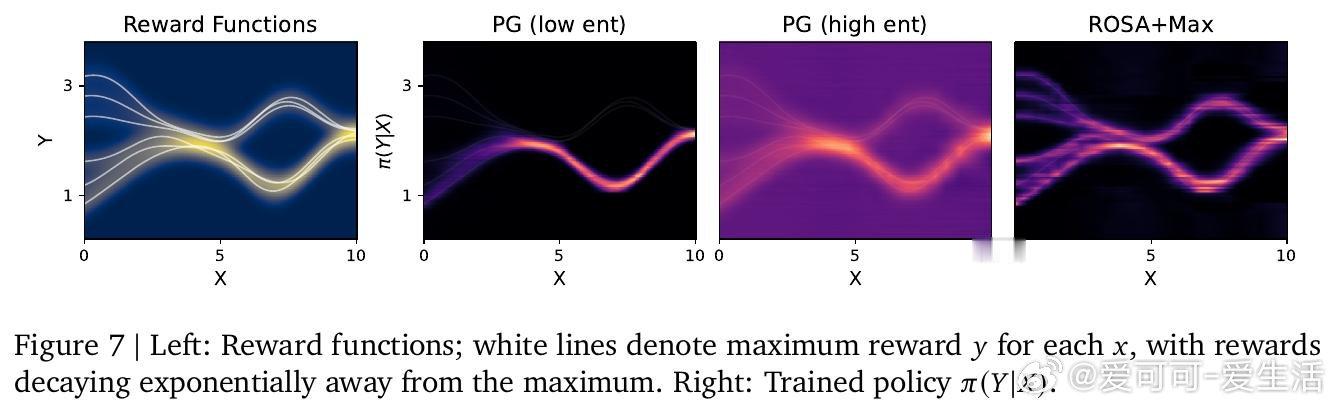
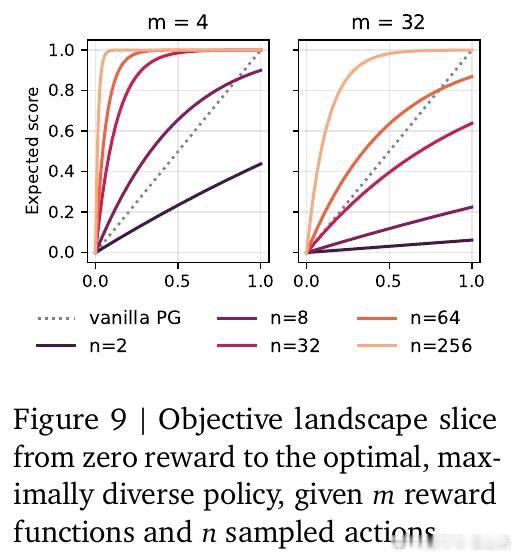
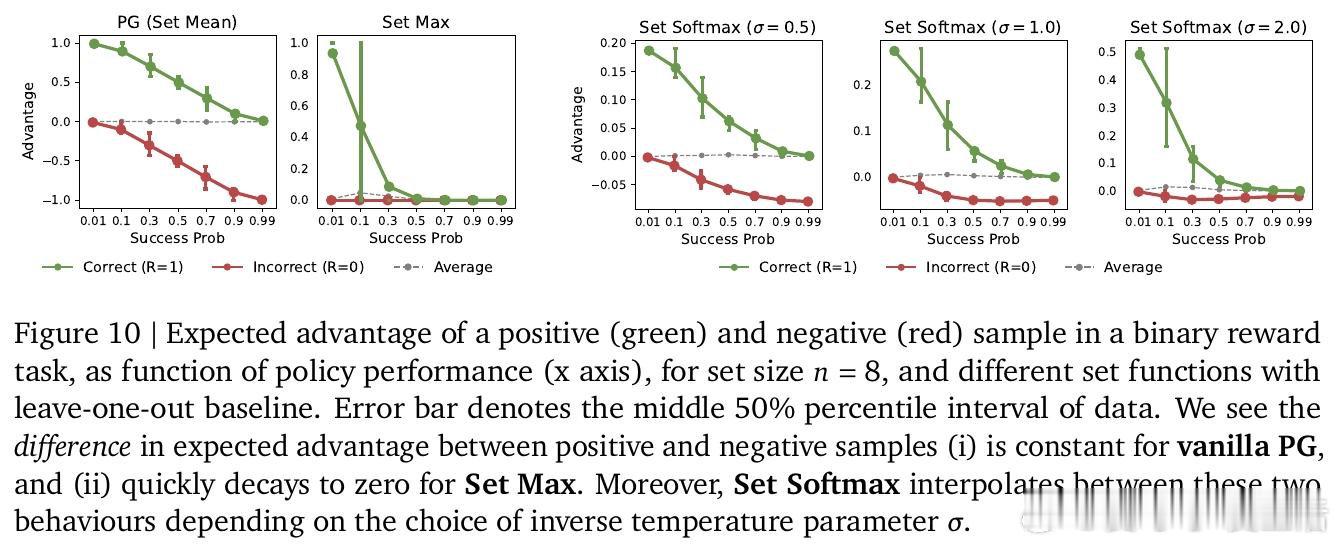
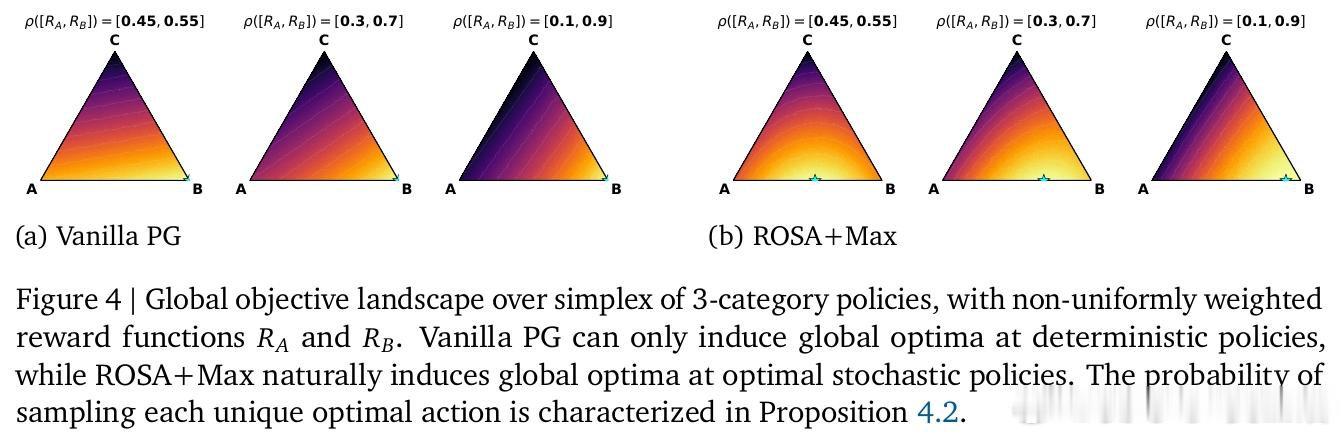
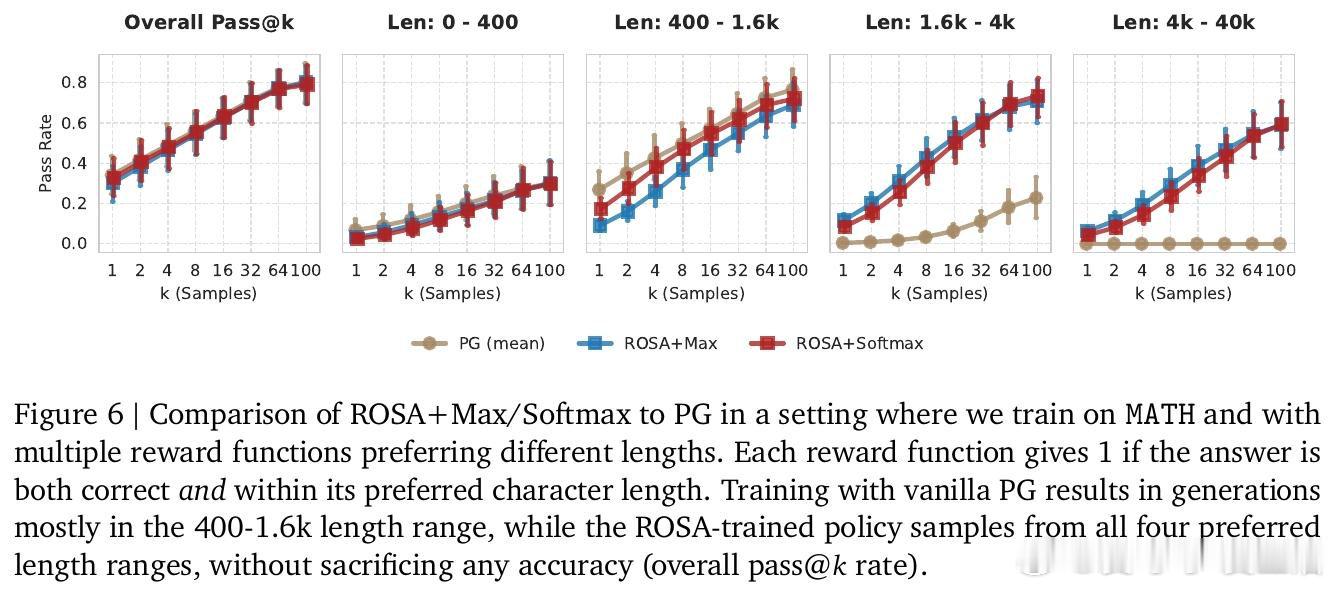
[LG]《Using Reward Uncertainty to Induce Diverse Behaviour in Reinforcement Learning》A GX-Chen, A Anand, G Comanici, Z Abbas… [Google DeepMind] (2026)
在大型语言模型推理中,重复出现的多步推理套路总被困在临时草稿里。过去的方法依赖手写任务分解或复用整条轨迹,本质原因是没有把“推理动作”当成可沉淀、可复用的单位。
本文的核心洞见是:把ReAct轨迹重新看作推理原语矿脉。由此,筛选成功轨迹、聚类Thought、合成伪工具这一操作,使模型能稳定调用曾经只偶然出现的推理动作,从而超越原始智能体性能。
这项工作真正留下的遗产是:推理经验可以从行为痕迹中自动结晶。它为后来者打开的新门是无需专家设计的推理工具库,但尚未跨过的门槛是原语仍依赖LLM解释,可靠性边界尚未完全明确。
arxiv.org/abs/2606.03962 机器学习 人工智能 论文 AI创造营