从编程角度介绍大模型应用(2):大模型聊天框怎么运作的
第一节:从编程角度介绍大模型应用(1) 网页链接
大模型聊天不是大模型本身,而是一个应用。大模型公司,或开发公司拿开源大模型,编出网页版、APP版的聊天程序。
在一个框里连续聊天,前后相关,大模型明显知道前面聊了啥。这有个最重要的概念:上下文(context)。大模型是怎么和我们一句句聊的?
从编程角度来理解,关键是聊天程序调用大模型吐词,它还要组织上下文。大模型刚开始流行的时候,输入一句话叫prompt(提示词),大模型会输出一句回应,这中间就调用了一次大模型。
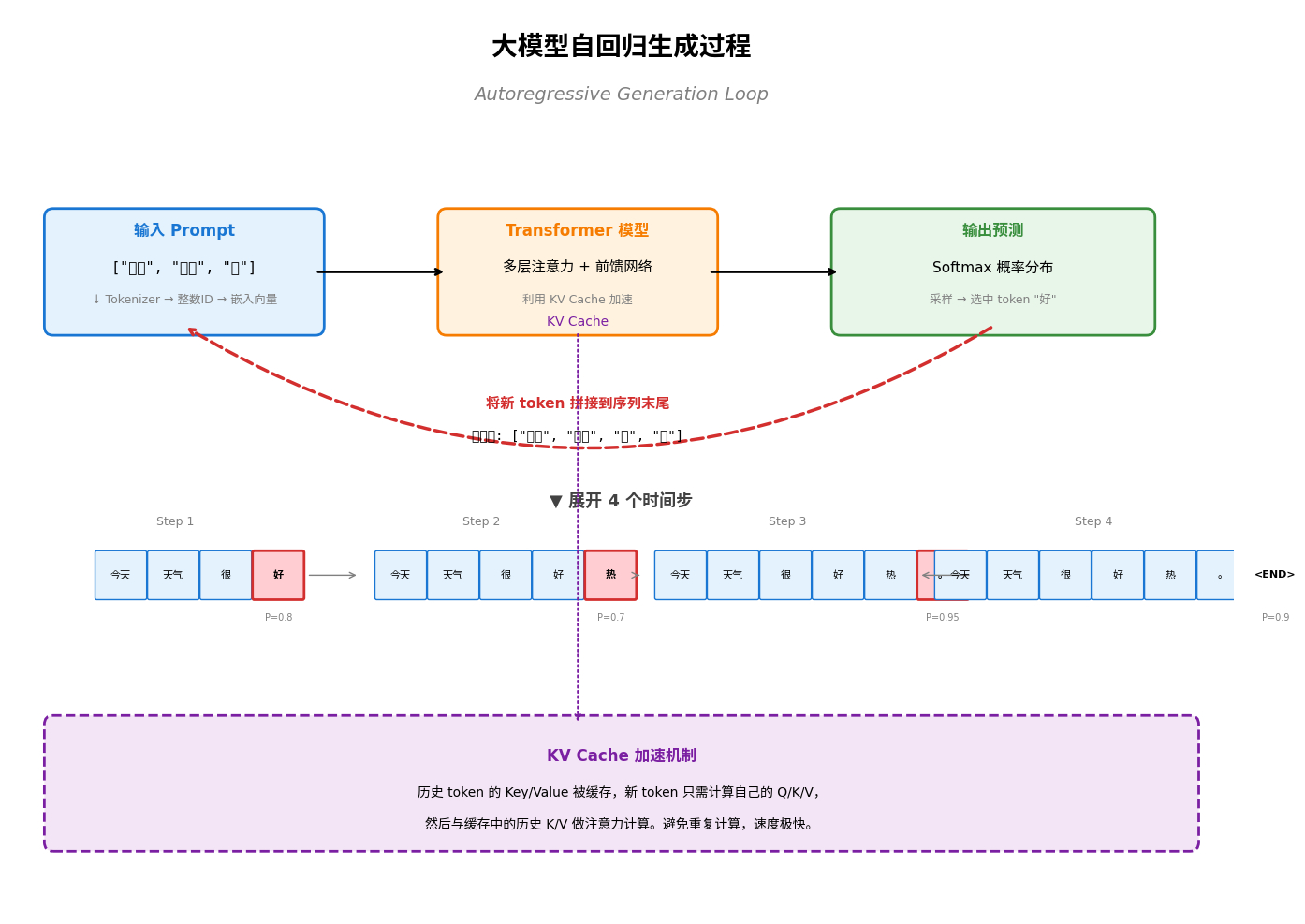
调用大模型,就是给它个输入,它给出个输出。我们输入一句prompt,如“今日天气”。大模型会先调用tokenizer,把它变成几个token(简单理解,就一个字对应一个token)。但每个token有好几千维的数据,DeepSeek V3是7168维,100个token输入,会拼出个100*7168维的输入矩阵。大模型最直接的输入,其实是这个矩阵。
纯聊天不用管tokenizer。编程调用大模型时,要写代码调用tokenizer函数,计费、上下文管理按token数算,知道了有好处,太大了要处理。tokenizer和大模型绑定了不能换,也可以当成大模型的一部分。
100*7168的输入矩阵,在大模型里跑矩阵运算,神经网络一级级推理,最末一级会输出“一个token”。例如,“今日天气”输入给大模型,它会输出一个token,例如“好”字,例如“很”字,都行。实际最末一级输出的是“概率组合”,每种token的概率。一共14万种token,绝大多数概率是零接不上。输出时选概率最大的,或随机挑个合理的,用“温度”参数控制输出多样性。
聊天时会看到大模型一个个吐字,就是算了一个token。吐不少字后最后输出,这是一个“自回归”过程。新吐的那个token加在之前的prompt后面(如变成“今日天气很”),输入矩阵增大。不用tokenizer,输出的token直接拼,变成101*7168的输入矩阵。又重复跑一遍推理,又得出一个新的token(“今日天气很好”)。
第二次计算会发现,101*7168维的矩阵绝大部分和之前一样,不用重新算,用之前保存的“中间结果”就行,新加的那个才算。这中间结果学名叫KV Cache,体积十分巨大,就是它把内存股干到天上去了。
新算一个token,KV Cache也更新一些。如此重复不断吐token,最后一步输出一个“停止”token,就全结束,整体输出给用户。这是聊一句的过程。
接着人们又来一句,这要解释下。聊天程序要精心组织上下文,把“第一次输入”+“第一次输出”+“第二次输入(tokenizer后变成矩阵)”拼成一个更大的输入矩阵,发给大模型去算。第一次留下的KV Cache(包括第一次输出的token相关的)很有用,整体上吐字挺流畅。但第一个字吐得稍慢,对应了“预填充”(prefill)动作。KV Cache从缓存里读进来要点时间,但不是主要的。
预填充时,拼接后输入矩阵增大了一些,如加了100个token,前面输入输出有5000个,矩阵就是5100*7168的。大模型的核心机制是“自注意力”,所有token互相建立关联。这100个新token自己内部、和5000个旧token建立关联,新输入信息就“融入”上下文了。融入完成,又一个个吐token输出第二句。
连续聊天就是重复,不断prefill,上下文加长,KV Cache变大。prefill代价逐渐加大,但还能接受。有时实在聊得太长,就超过大模型的上下文长度限制了。大模型有个关键参数,如128K 、256K上下文容量,如DeepSeek V4很强有1M。超过了大模型也能聊,就把前面聊的丢了,用户没注意也没事。
还有种情况,过了很久例如几天,再翻出聊天框接着聊。大模型公司保存的KV Cache早没了,就把所有输入和输出组织成一个长的上下文输入矩阵,像第一次那样算一遍,再把KV Cache建立起来。这种情况耗时会长些。
纯聊天算最简单的,大模型训练好了,对于给定的输入矩阵,真能给出合理的输出。这是神经网络基于概率算出来的,不神奇,聊得明显不对会被惩罚继续训练。连续聊天就是KV Cache不断增大的过程,都很自然。
现在聊天时普遍有“联网搜索 ”了,这个不简单,细节更多,下节聊。