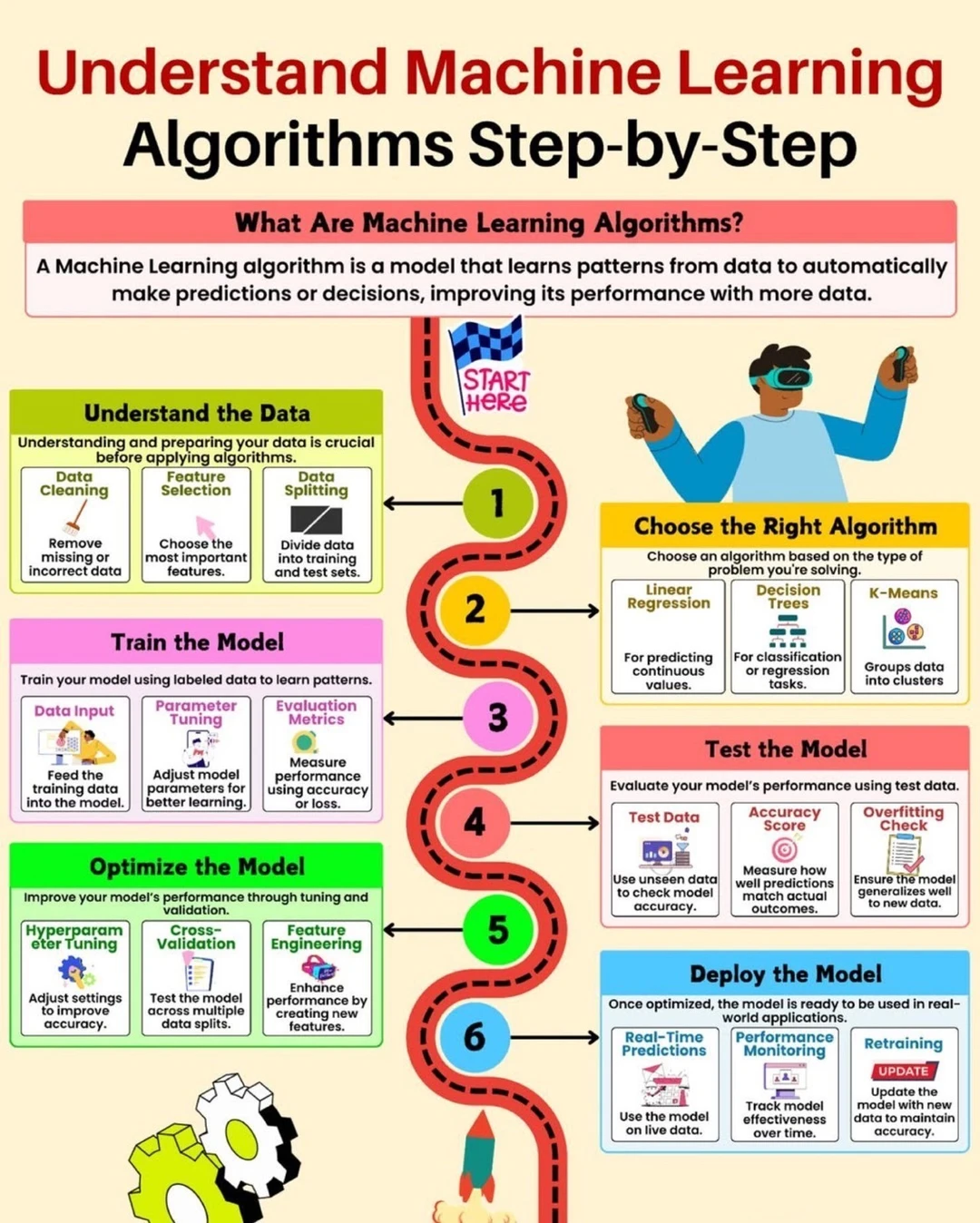
机器学习本质是一种模型,它通过从数据中学习规律,自动做出预测或决策,并且随着数据增加不断优化表现。简单来说,就是让机器“越用越聪明”。
📊理解数据是第一步
在真正建模之前,最关键的是处理好数据。包括清理错误或缺失数据、挑选最重要的特征,以及把数据分成训练集和测试集。数据质量往往决定模型上限。
🧠选择合适的算法
不同问题对应不同方法,比如线性回归适合预测连续数值,决策树适合分类或回归任务,K均值用于聚类分析。选对方法,比盲目堆技术更重要。
⚙️训练模型的核心过程
把数据输入模型,让它学习模式,同时不断调整参数以提升效果。通过准确率或损失函数来评估表现,这一步决定模型是否真正“学会”。
🔍测试模型是否靠谱
使用未见过的数据进行验证,观察预测准确度,并检查是否出现过拟合问题。好的模型不仅能记住训练数据,还能适应新数据。
🚀优化模型提升表现
通过调参、交叉验证以及特征工程进一步提升效果。这一步相当于“打磨模型”,往往能带来显著性能提升。
🌐部署模型走向现实
当模型表现稳定后,就可以上线使用,比如实时预测、持续监控效果,并根据新数据不断更新模型,让系统长期保持准确。
🔥核心总结
机器学习并不是神秘黑盒,而是一条清晰流程:数据→算法→训练→验证→优化→应用。每一步都决定最终效果。
📈一句话看懂
真正的高手,不是会用模型,而是能把数据变成持续产生价值的系统